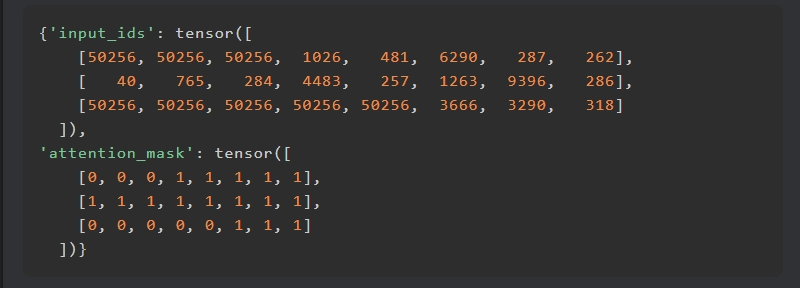
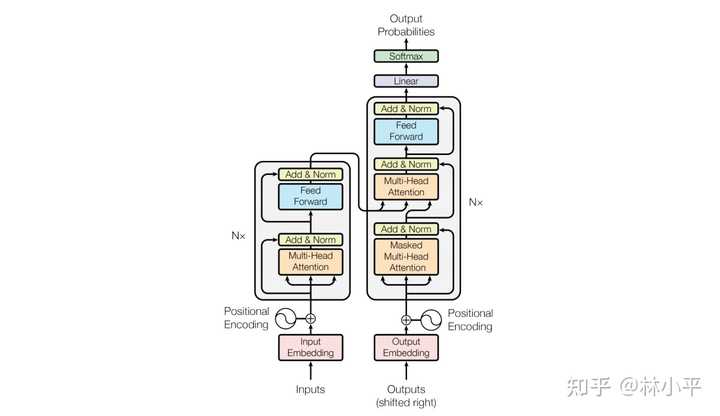
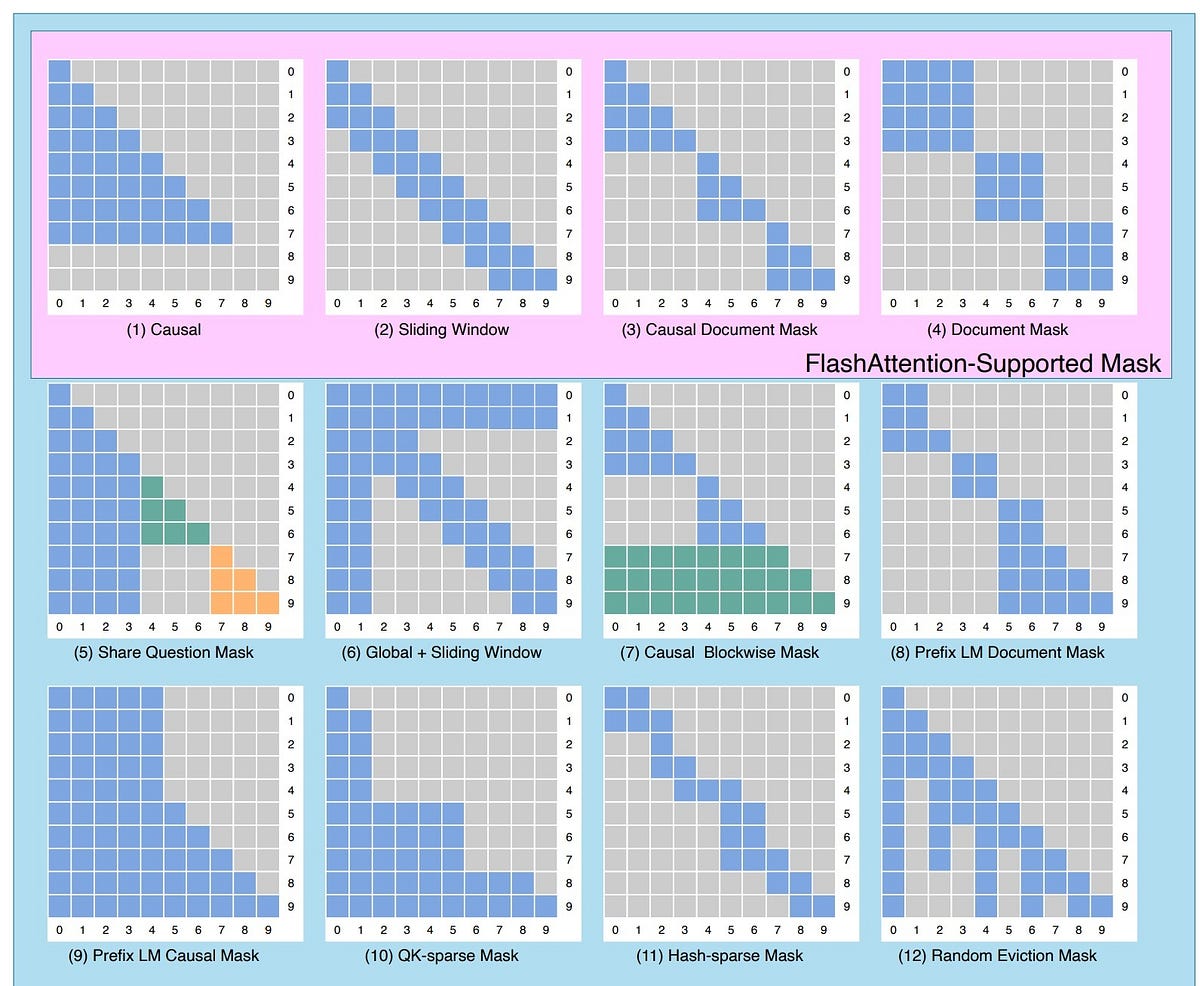
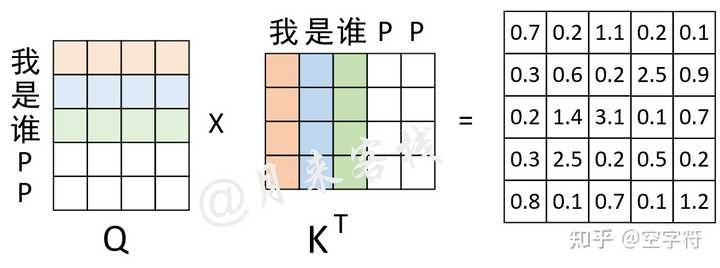
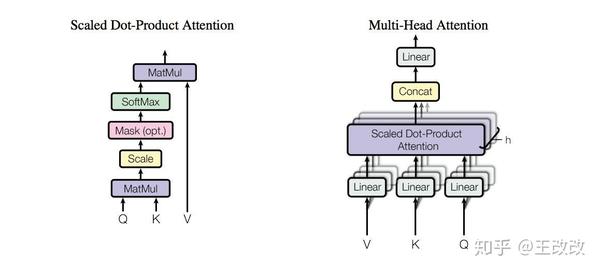
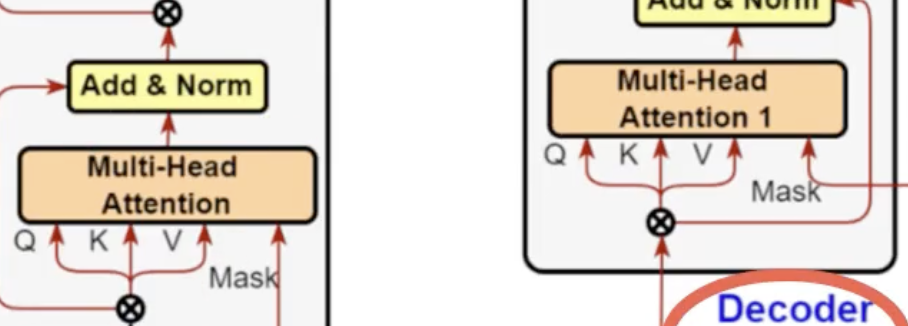
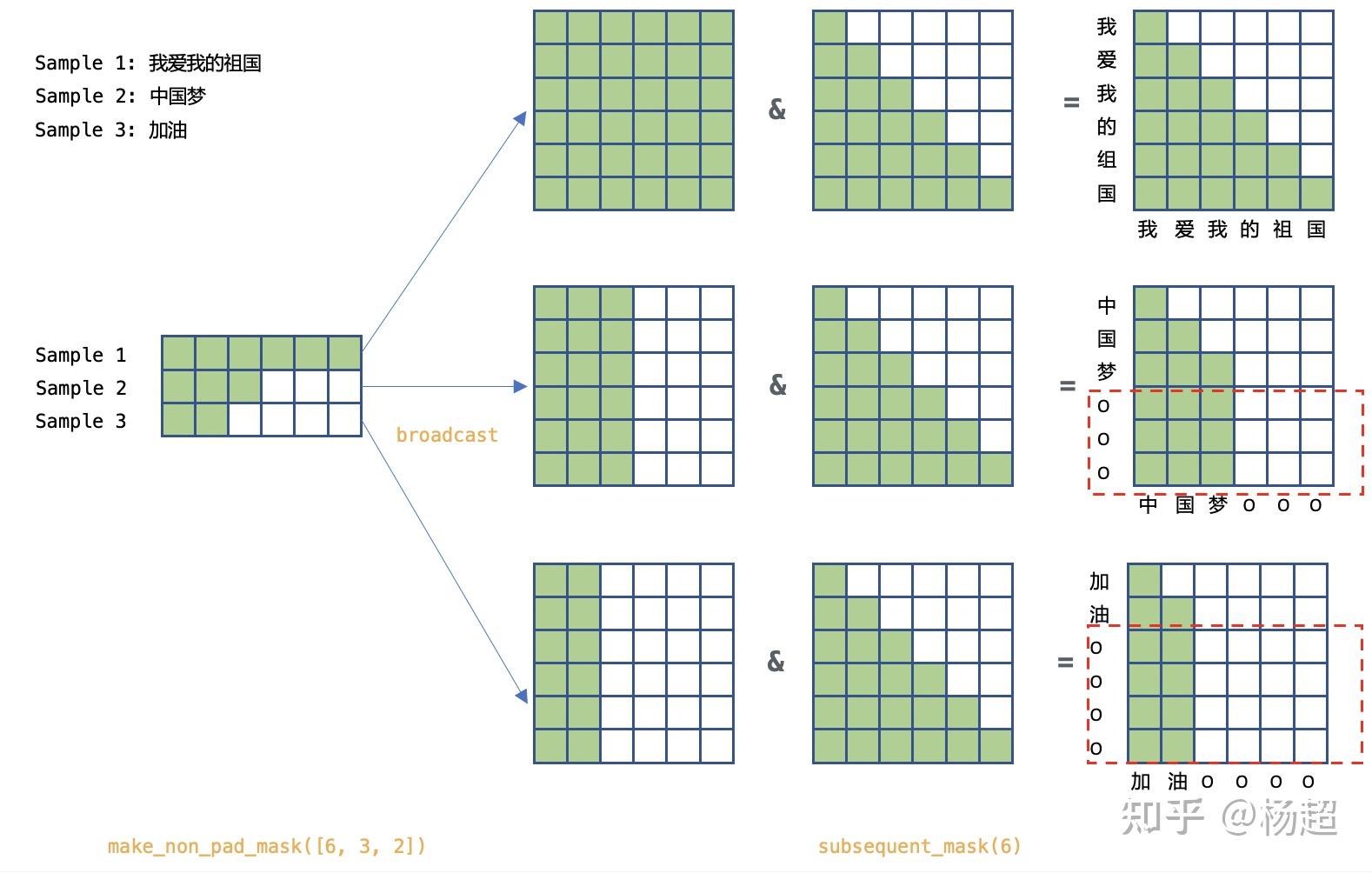
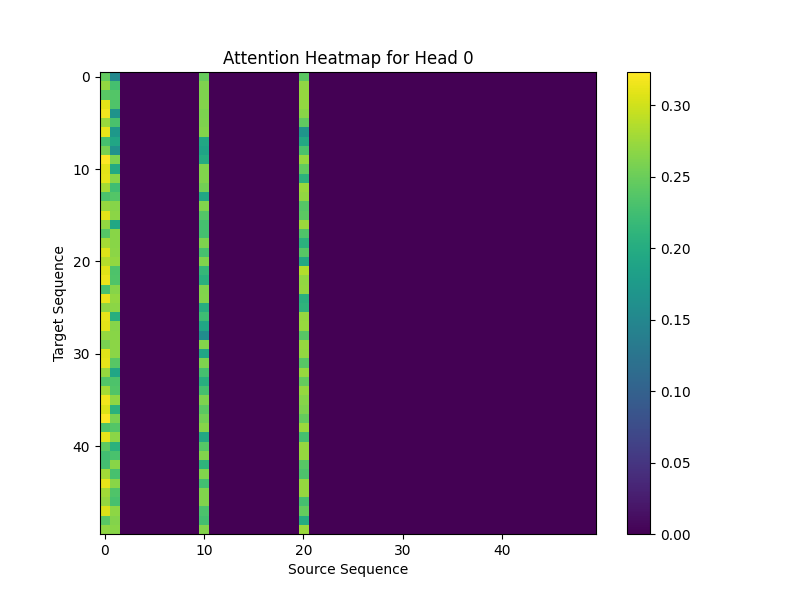
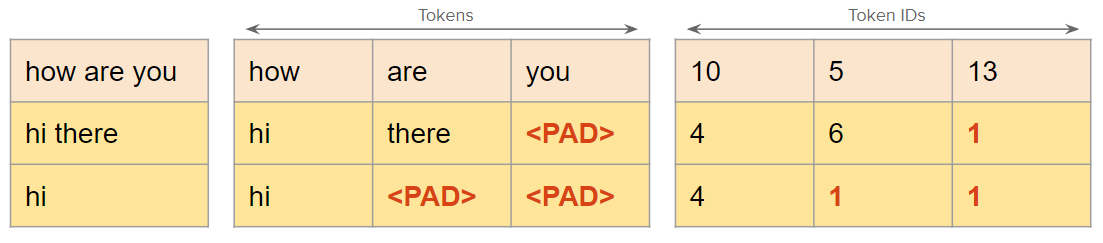
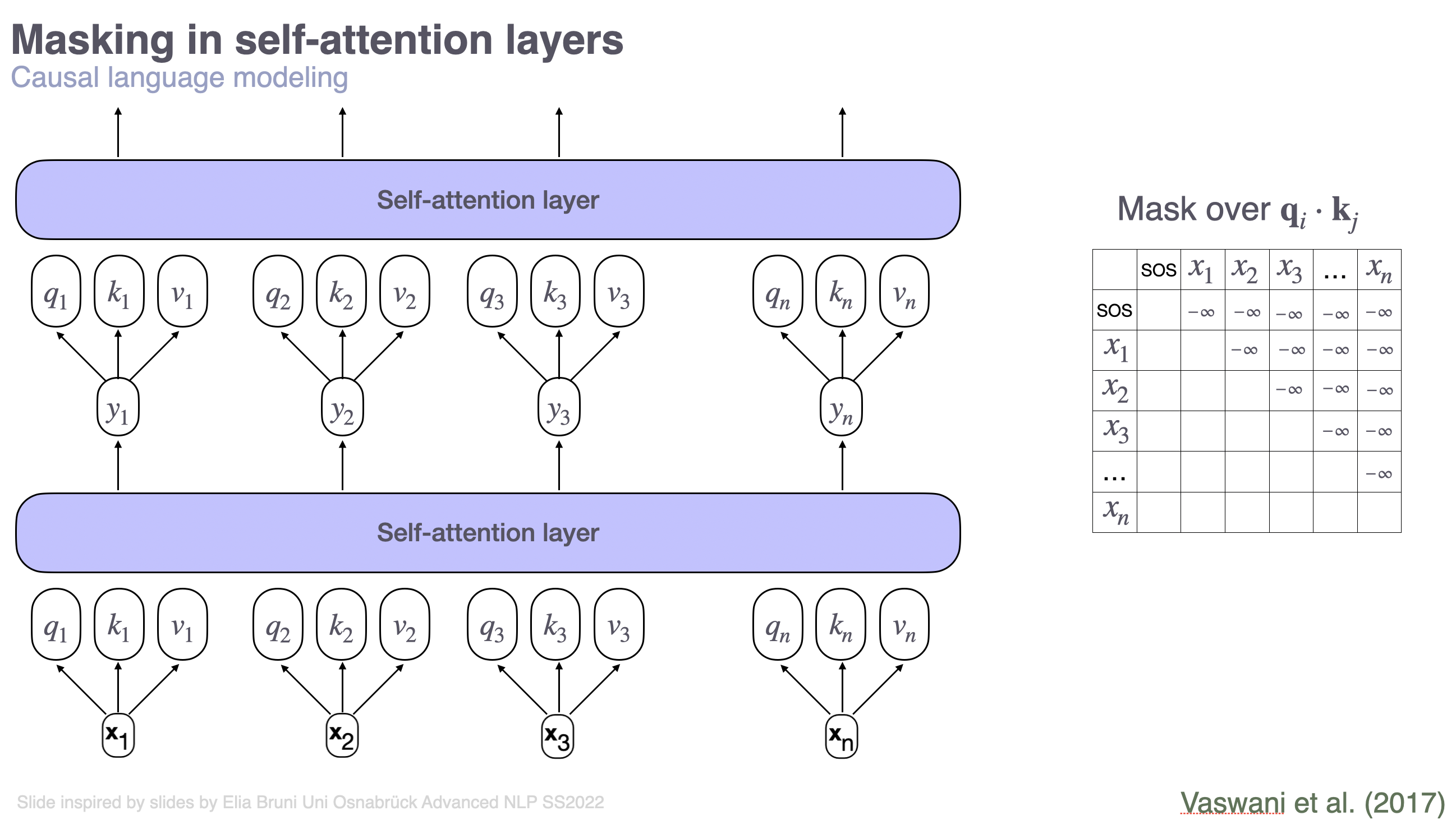
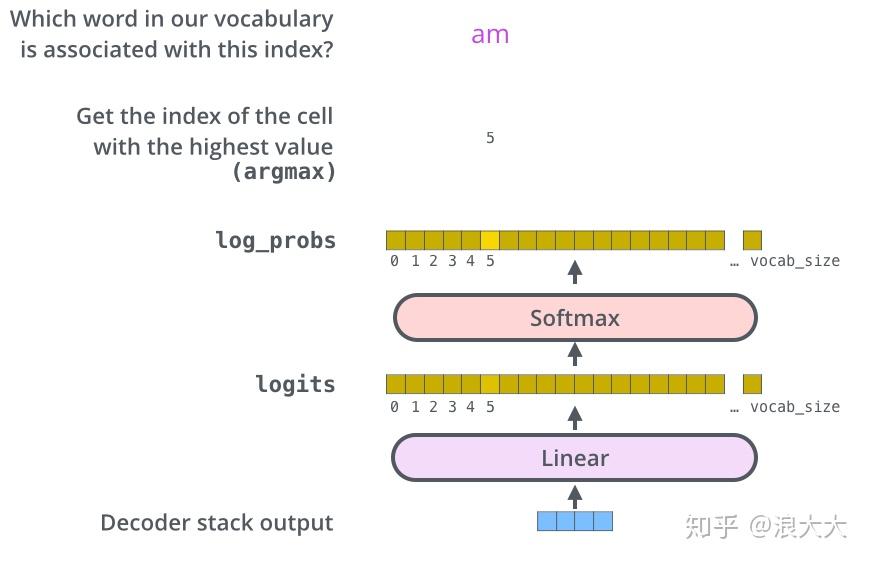
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
padding mask and attention mask · Issue #11 · tatp22/linformer-pytorch ...
python - Query padding mask and key padding mask in Transformer encoder ...
Padding mask in attention - nlp - PyTorch Forums
Use padding mask for attention in SimpleTransformerClassifier · Issue ...
padding and attention mask does not work as intended in batch input in ...
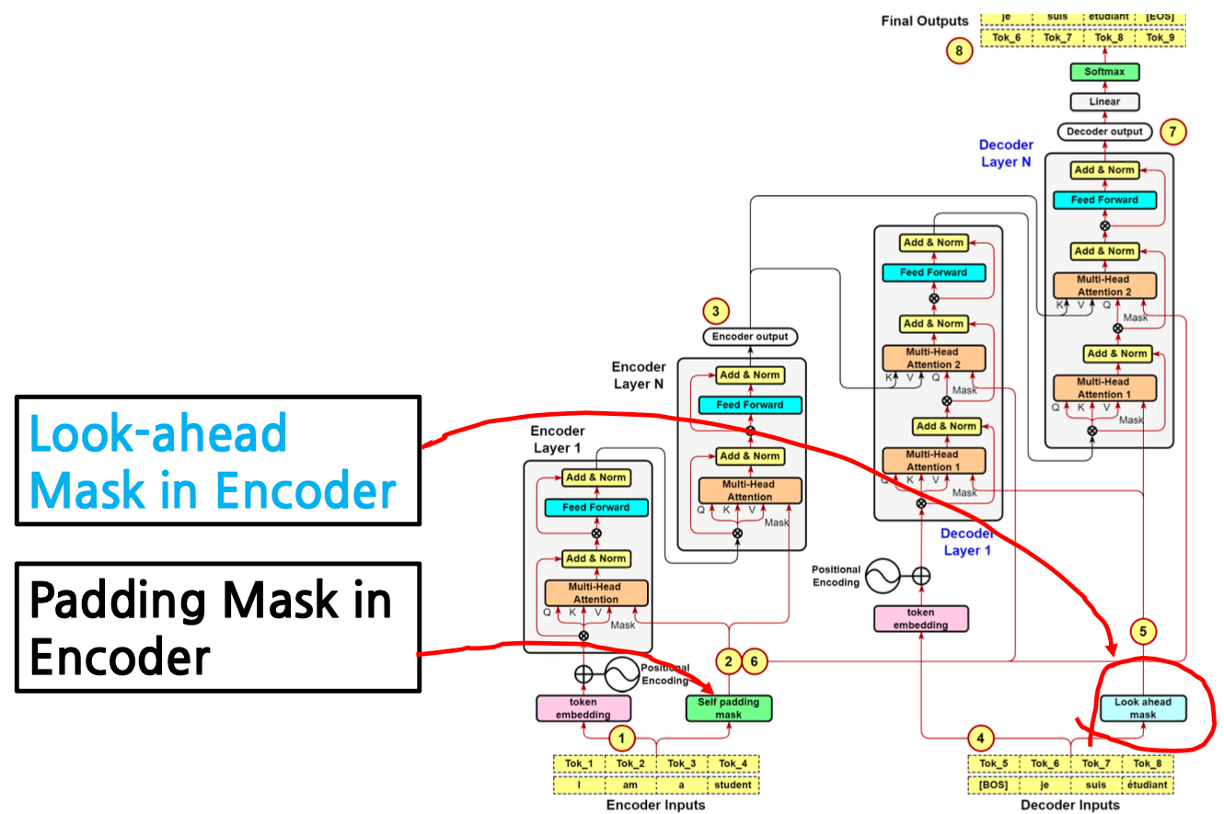
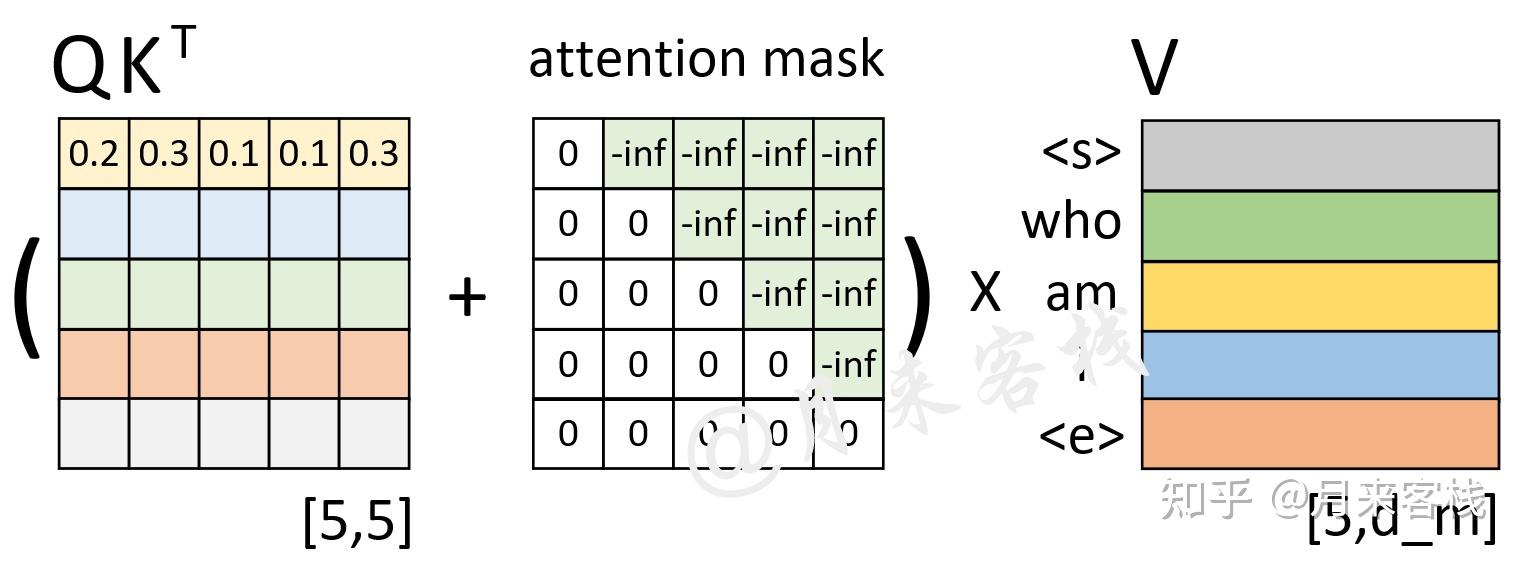
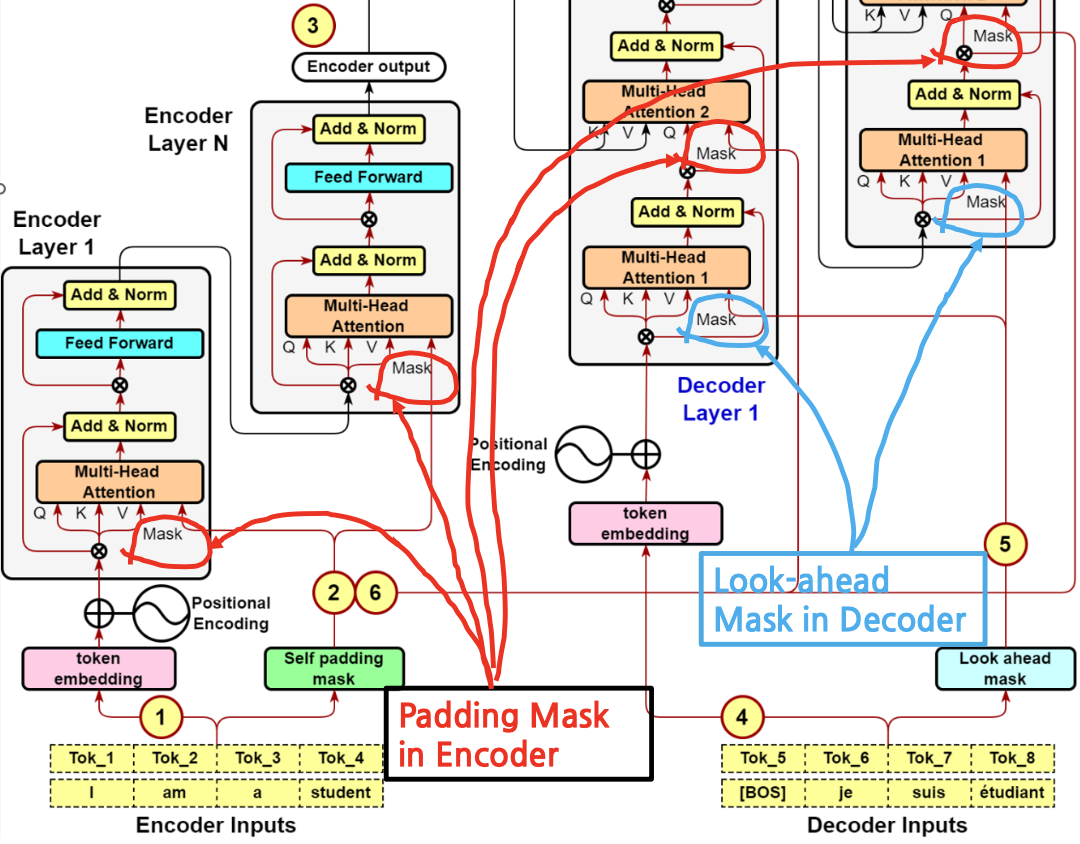
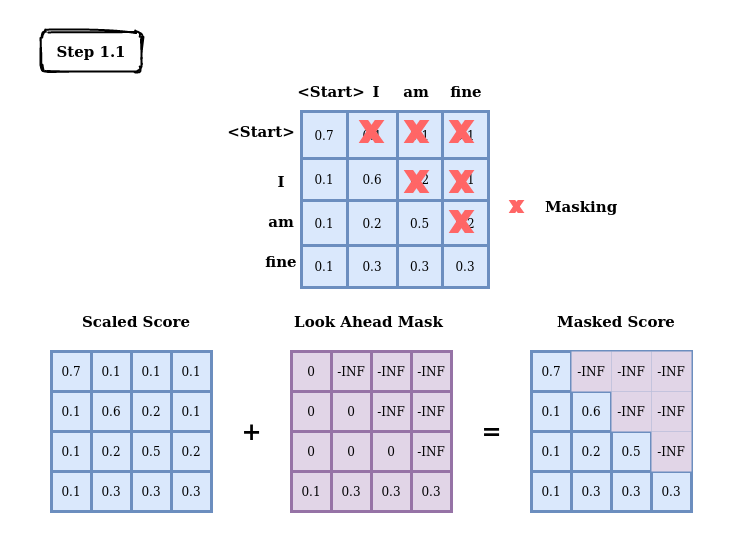
Padding and Look-Ahead Mask in the Transformer Decoder
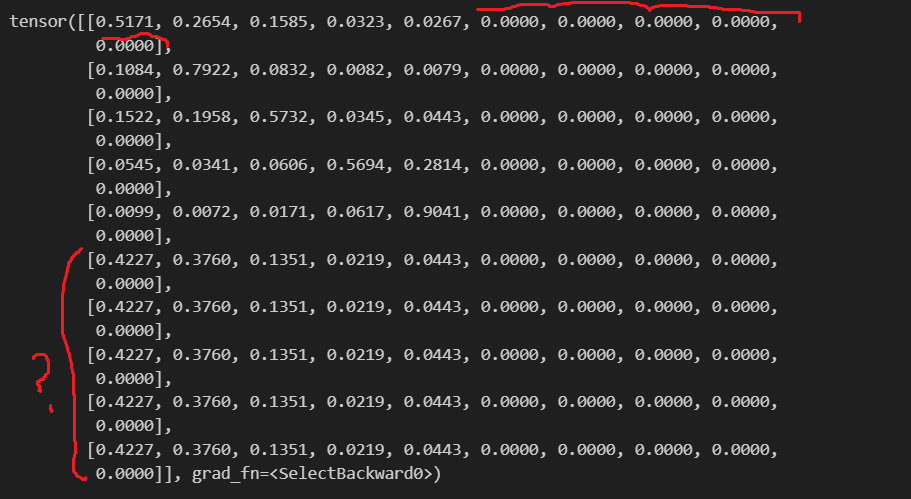
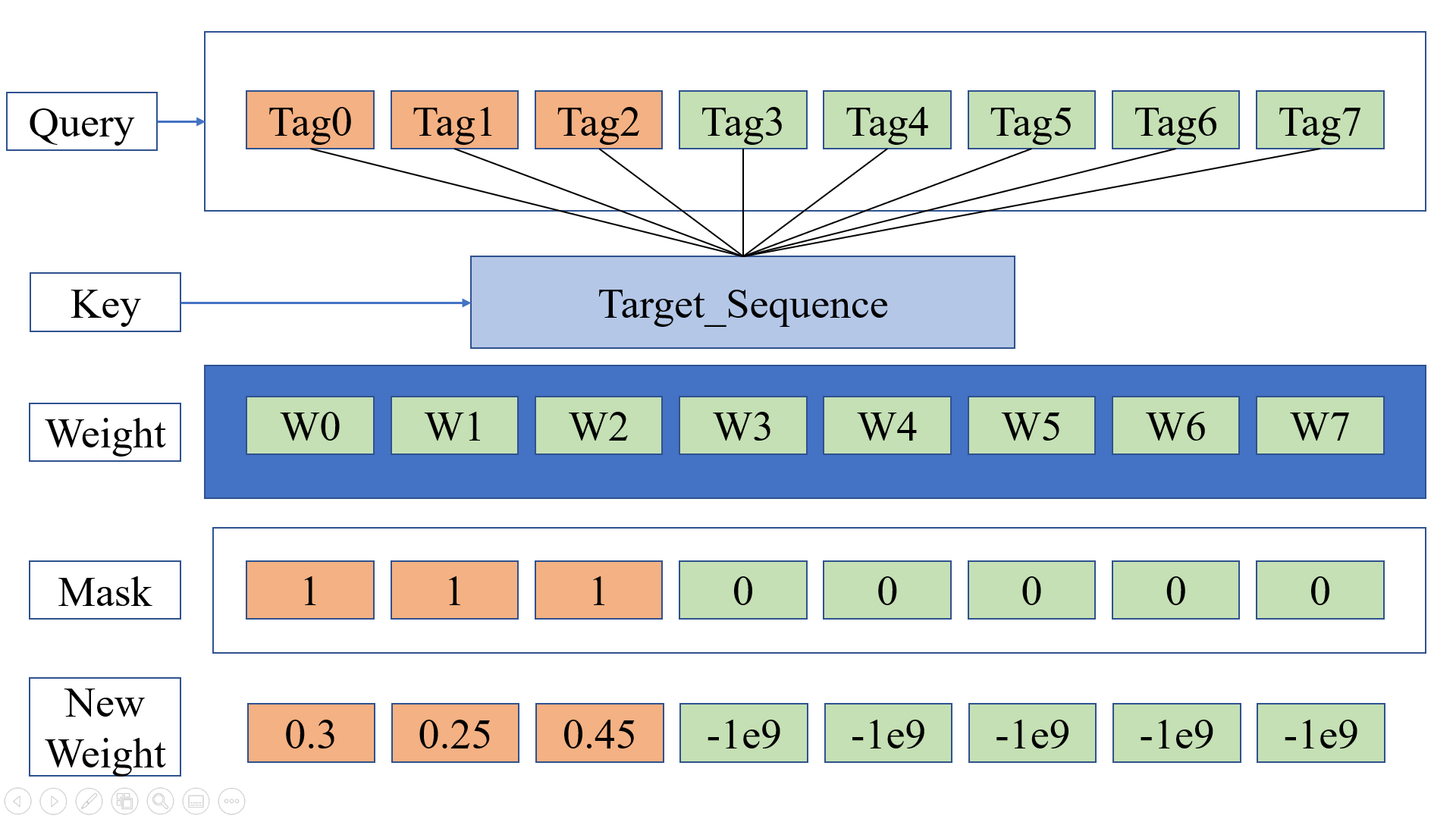
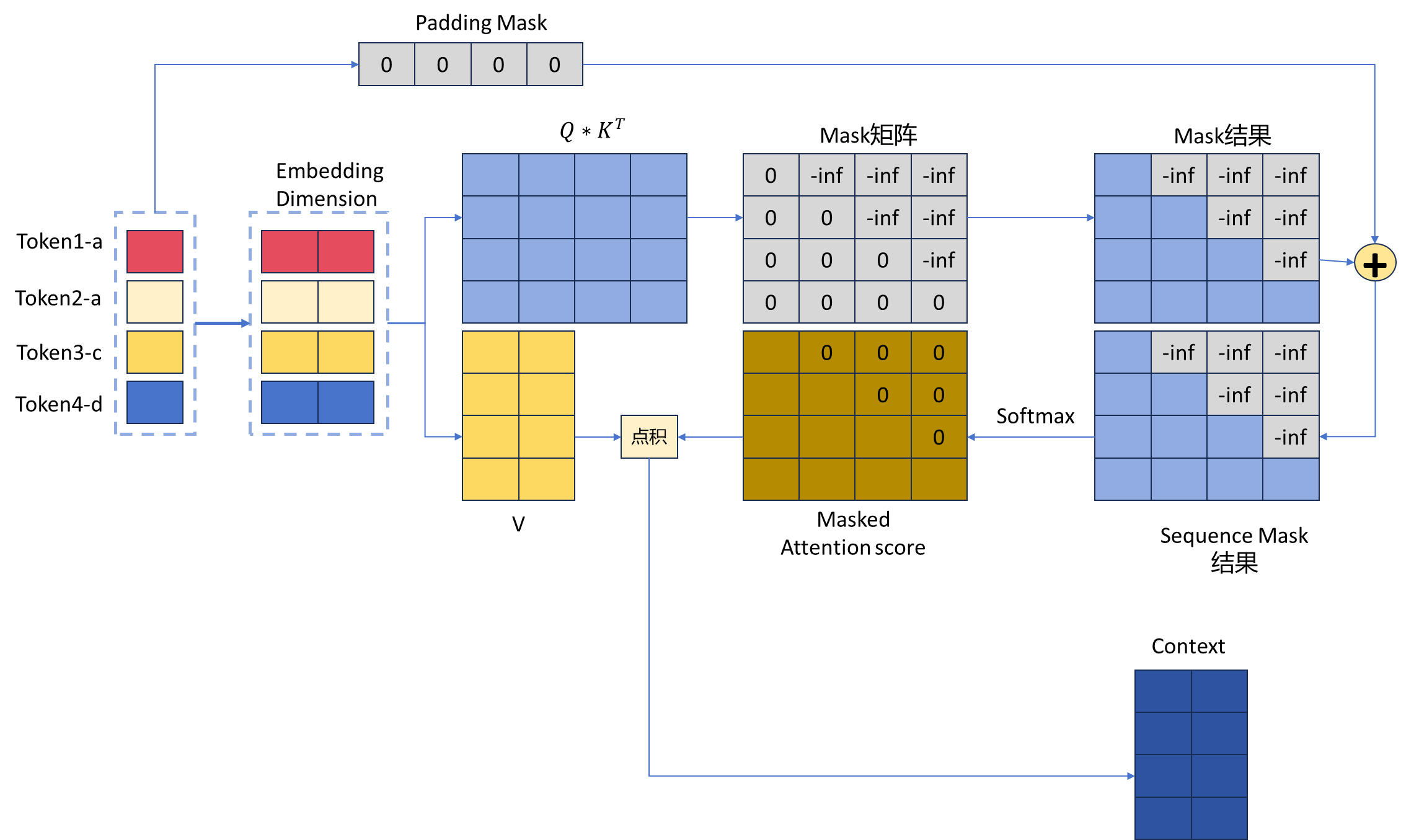
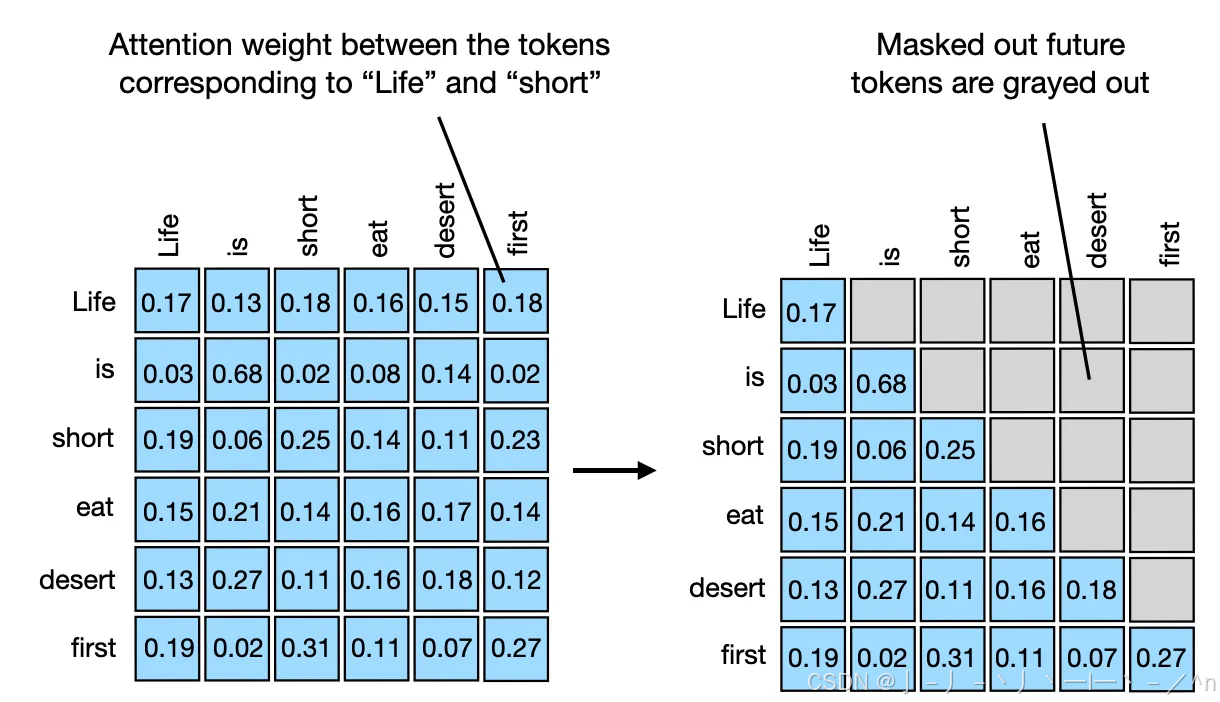
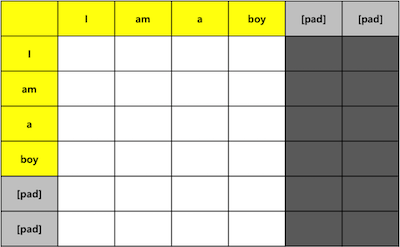
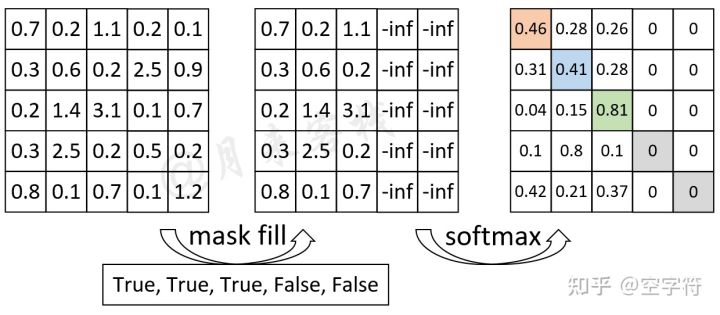
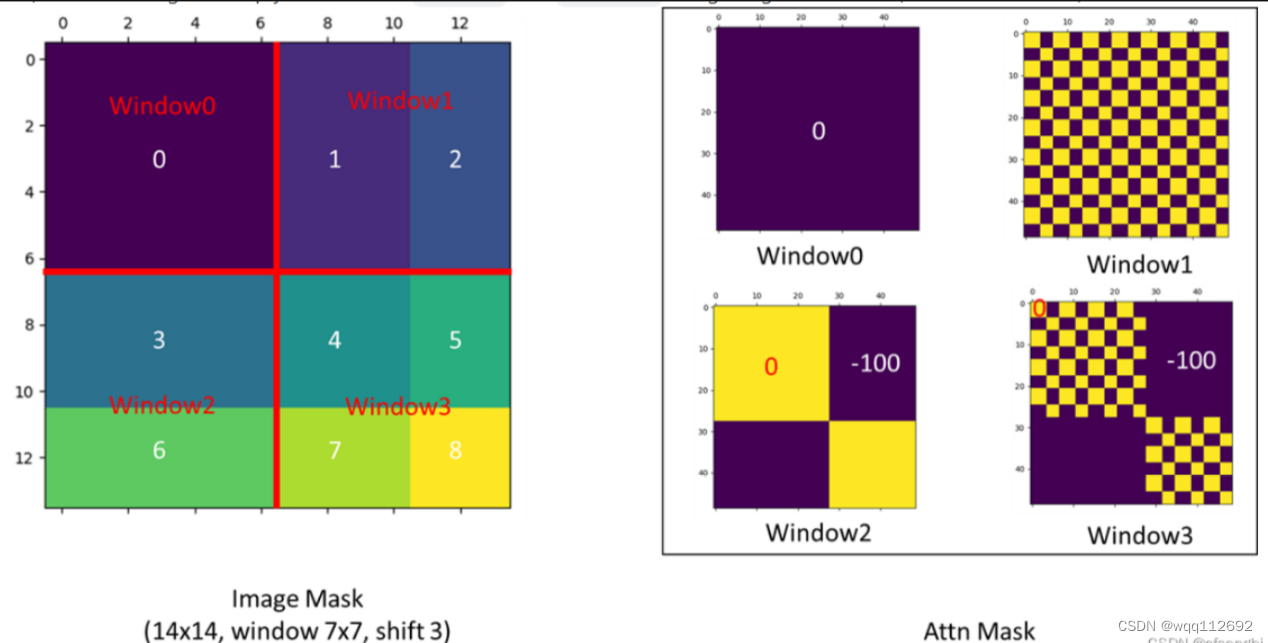
In Mask part, each padding elements will be multiplied by 0. In this ...
Special Tokens in Transformers: CLS, SEP, PAD, MASK & More ...
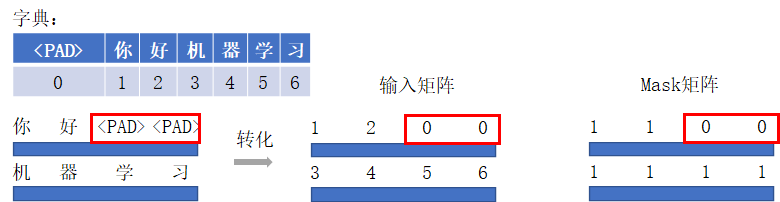
[机器学习]对transformer使用padding mask - 溡沭 - 博客园
DL0040 Attention Mask - Interview for Machine Learning
The Correct Attention Mask For Examples Packing - #4 by zhengyuyu ...
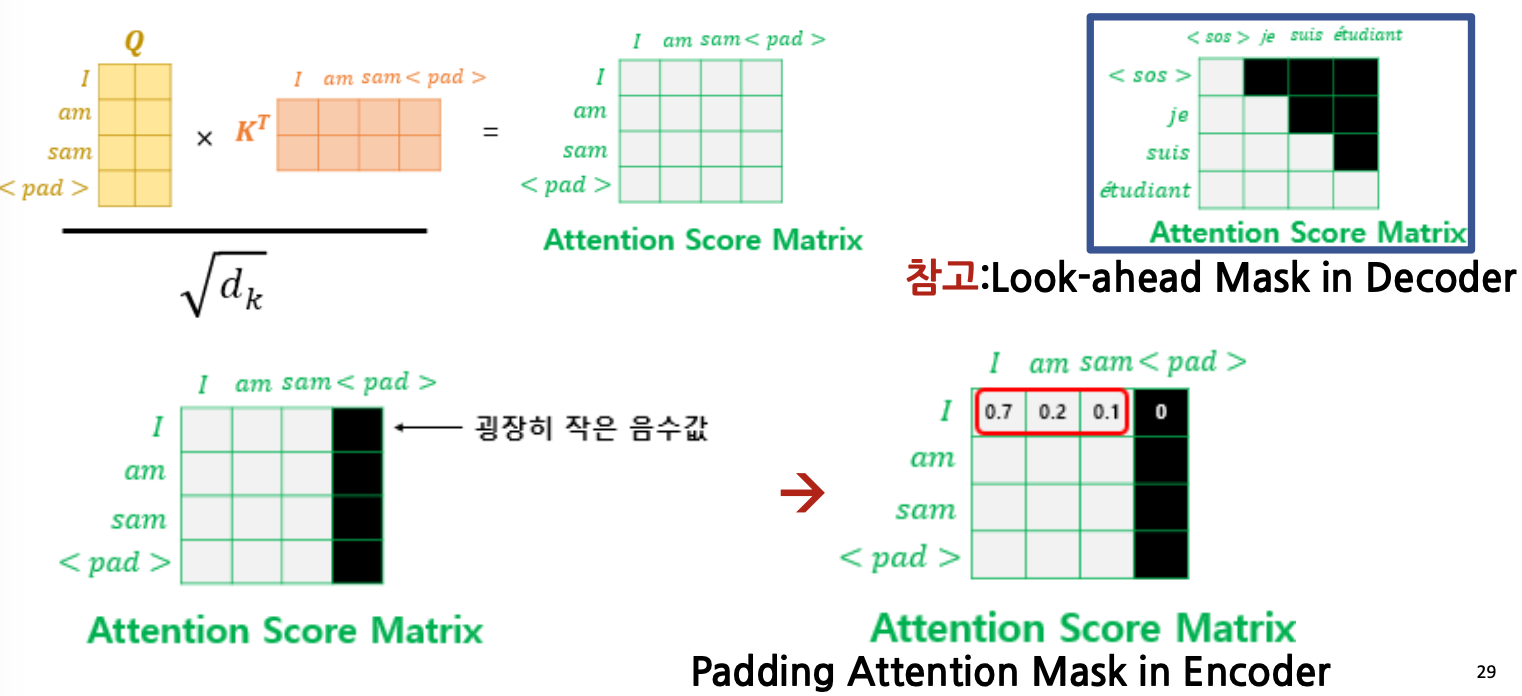
Intuition about the application of padding masks and look-ahead masks ...
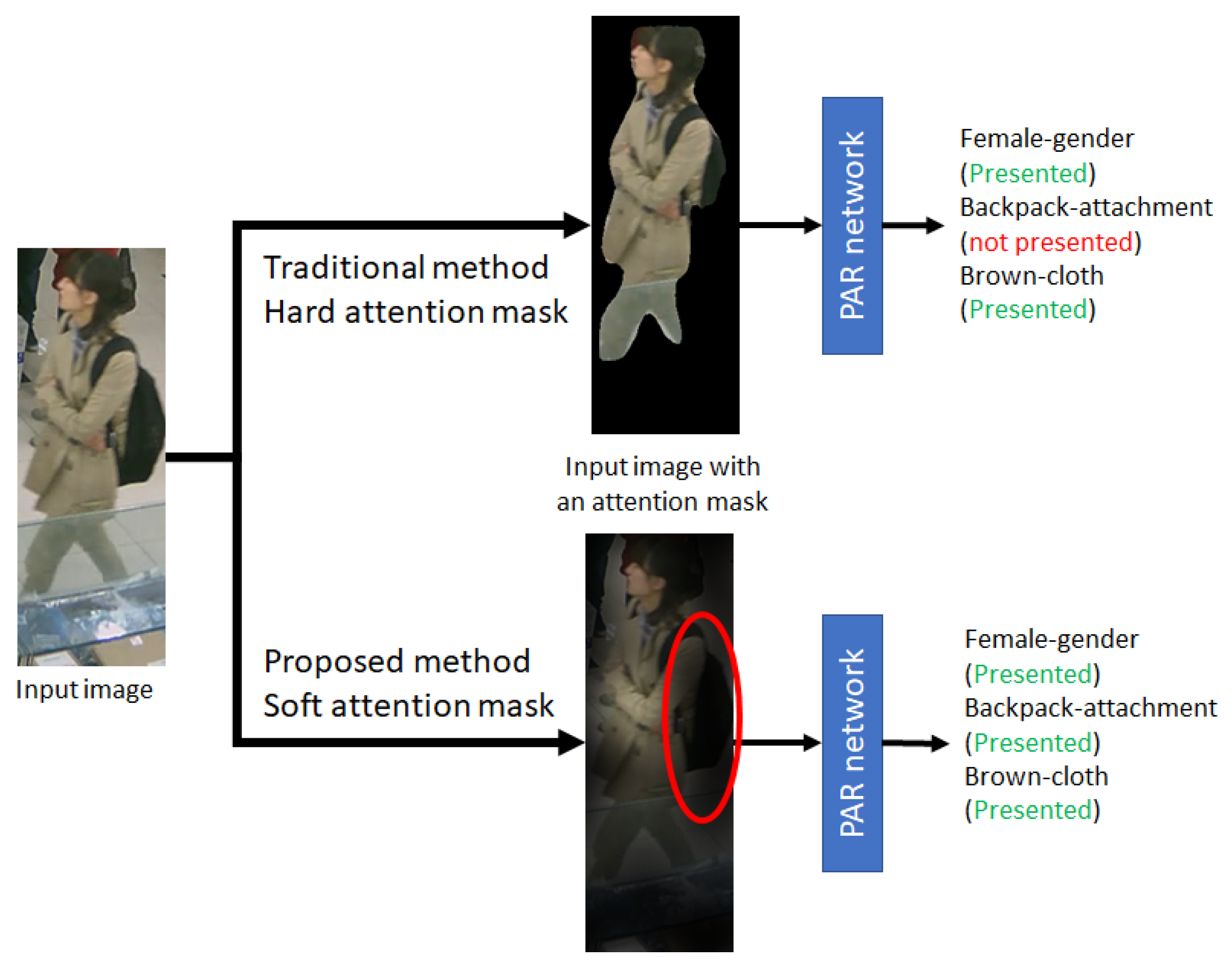
J. Imaging | Free Full-Text | Skeleton-Based Attention Mask for ...
Transformer模型-学习笔记_transformer padding mask-CSDN博客
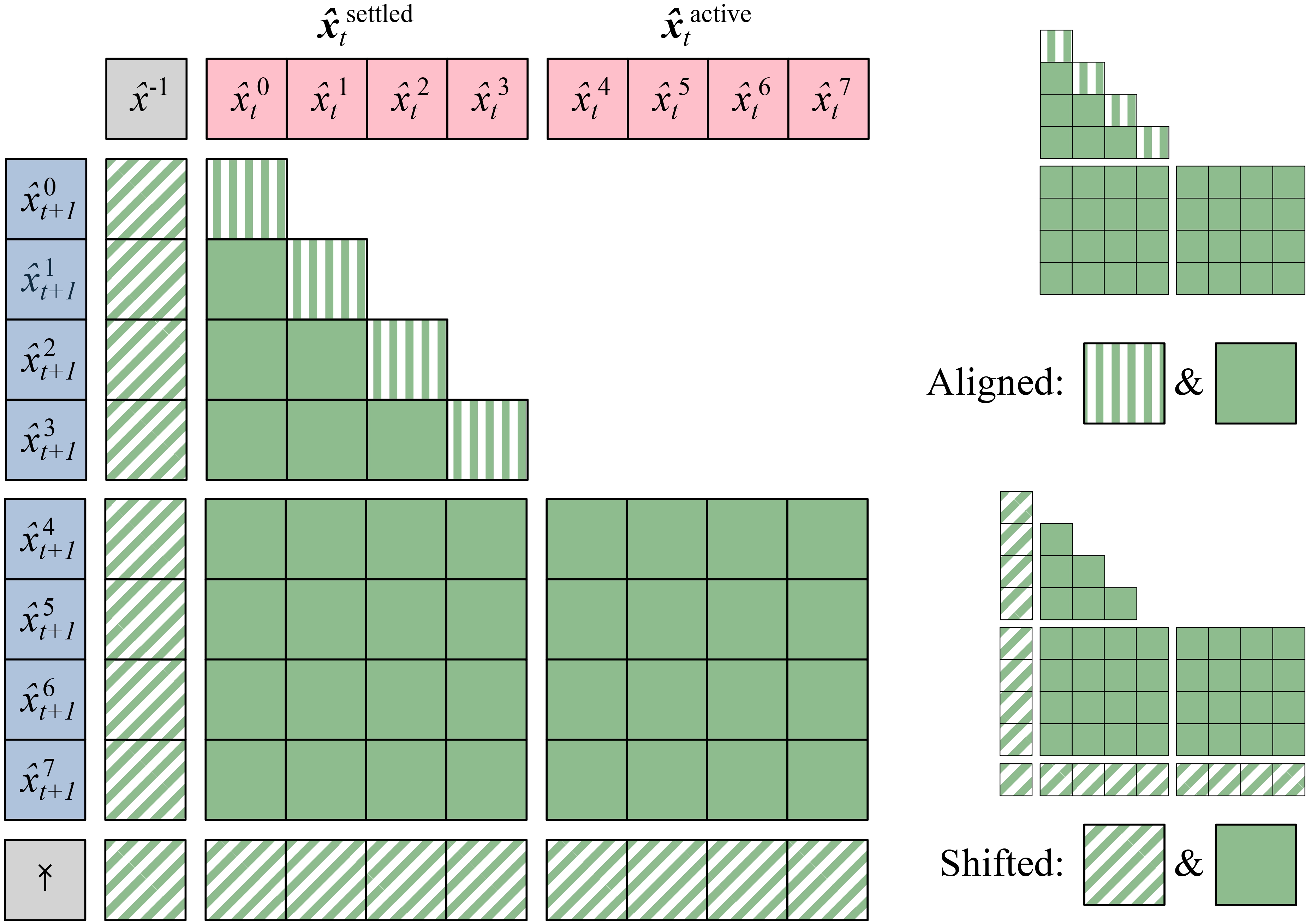
Overview of the Learnable Attention Mask Architecture. The Learnable ...
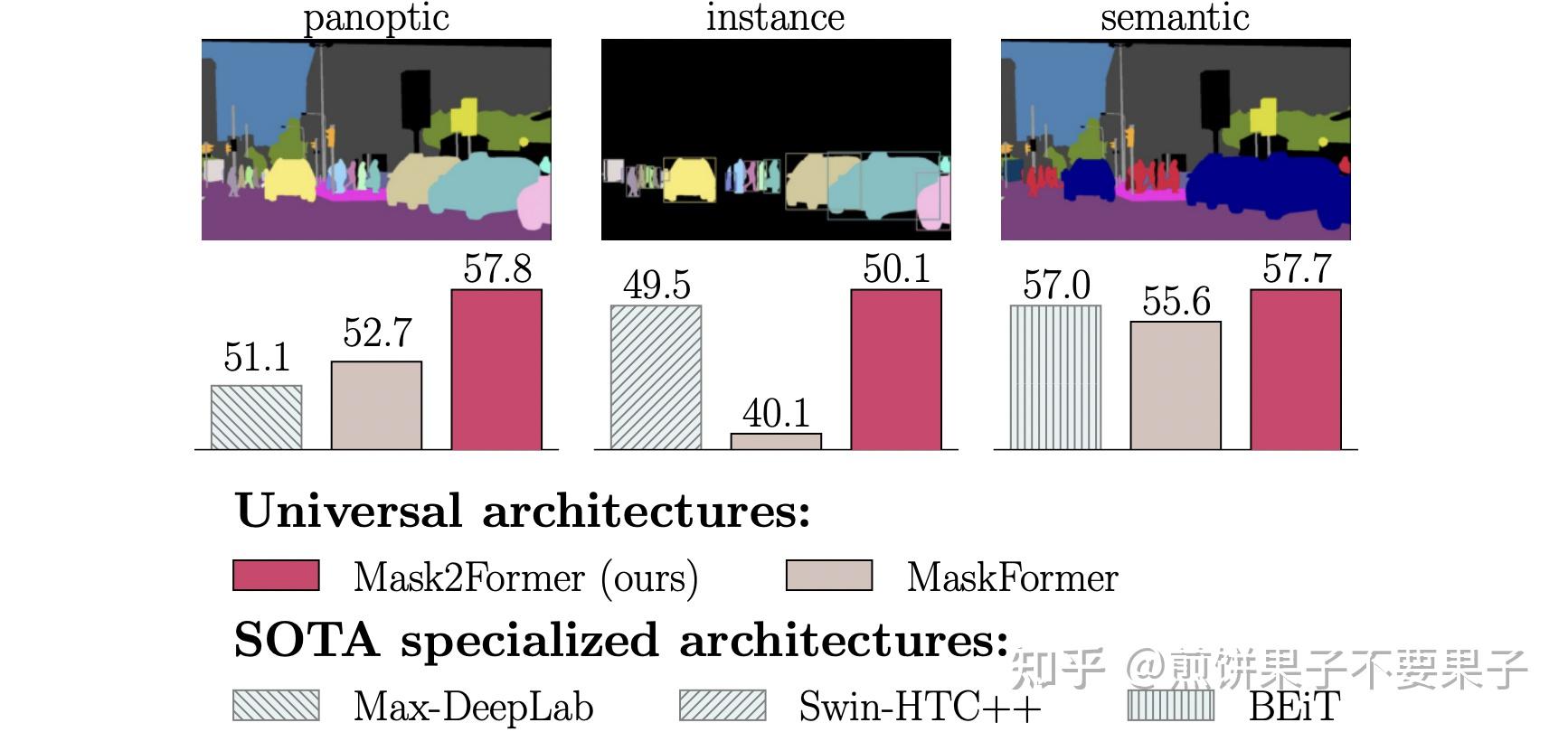
Masked-attention Mask Transformer for Universal Image Segmentation ...
Padding / attention_mask questions · Issue #36 · kzl/decision ...
How to implement seq2seq attention mask conviniently? · Issue #9366 ...
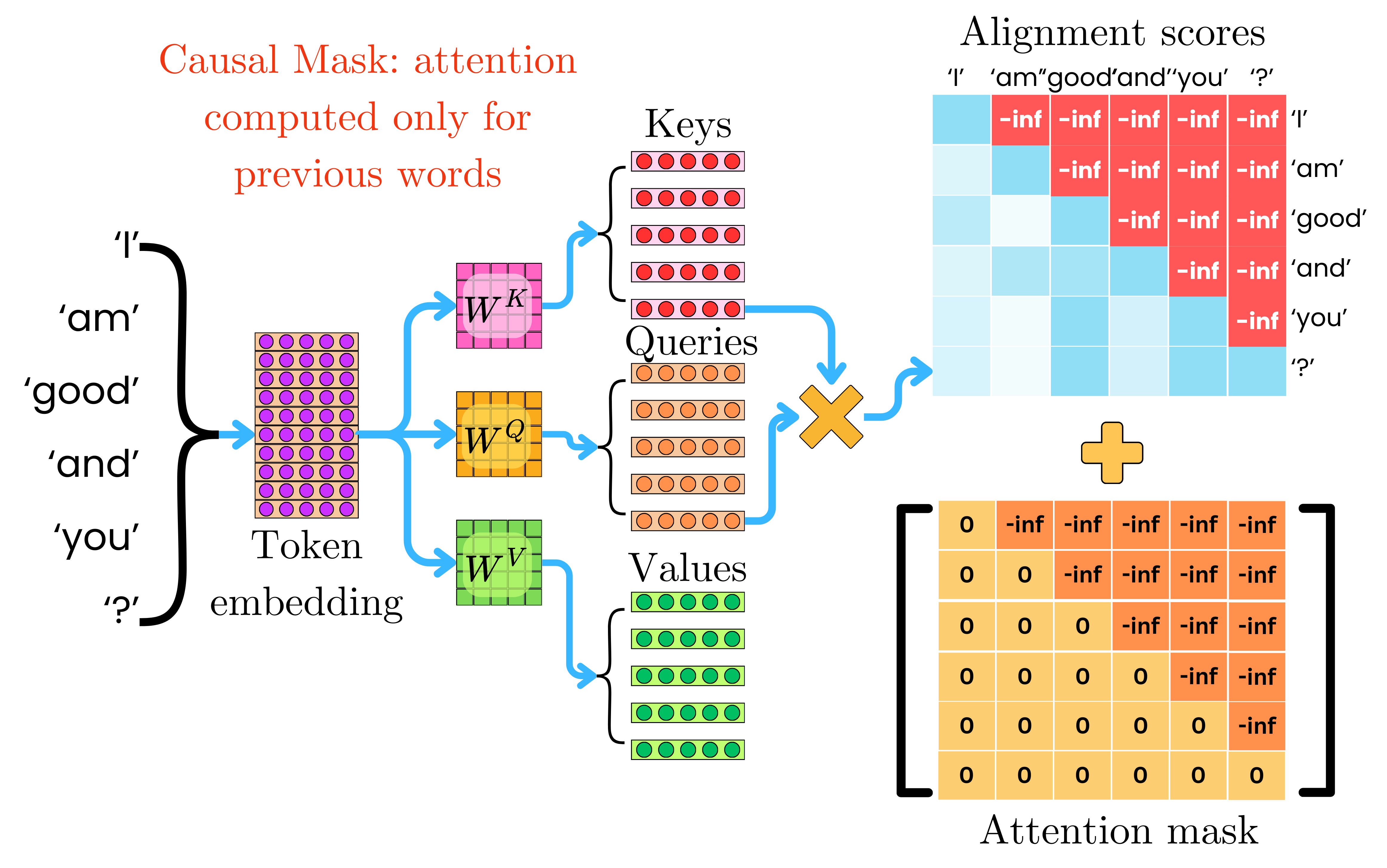
Simplified and shortened illustration of the attention mask for the ...
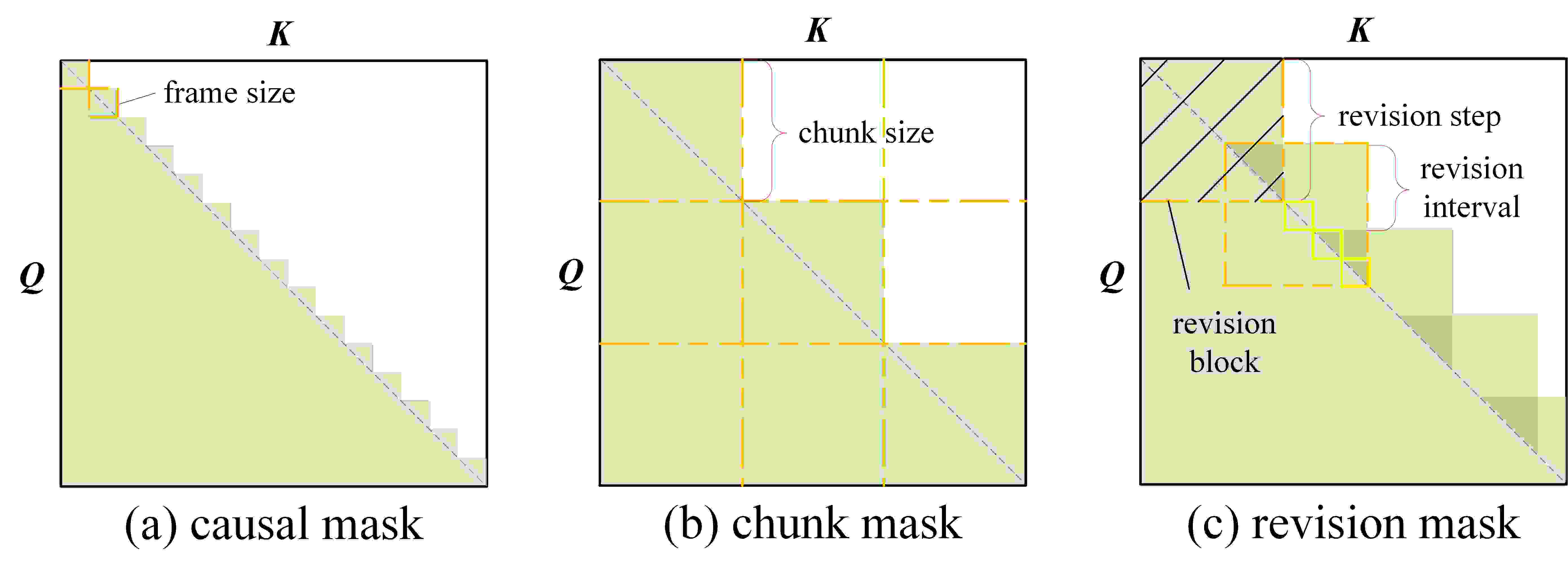
Causal attention mask in NTP modeling v.s. blockwise attention mask in ...
The attention mask is not set and cannot be inferred from input because ...
Transformer 源码中 Mask 机制的实现 - 虾野百鹤 - 博客园
Transformer结构解析(附源代码)_transformer padding mask-CSDN博客
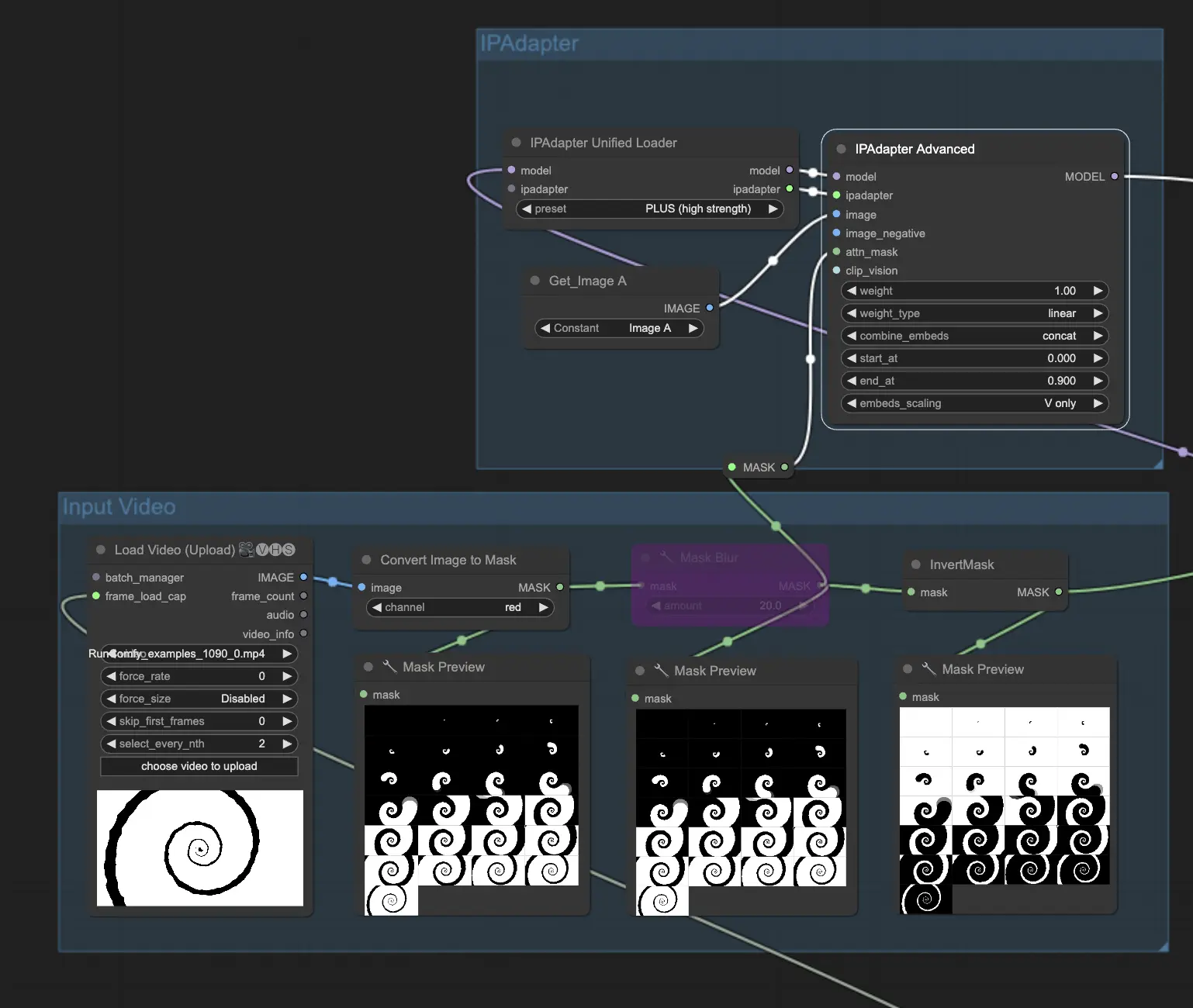
ComfyUI IPAdapter Attention Mask | ComfyUI Workflow
Transformer 中 Decoder 真的不需要 Mask - 知乎
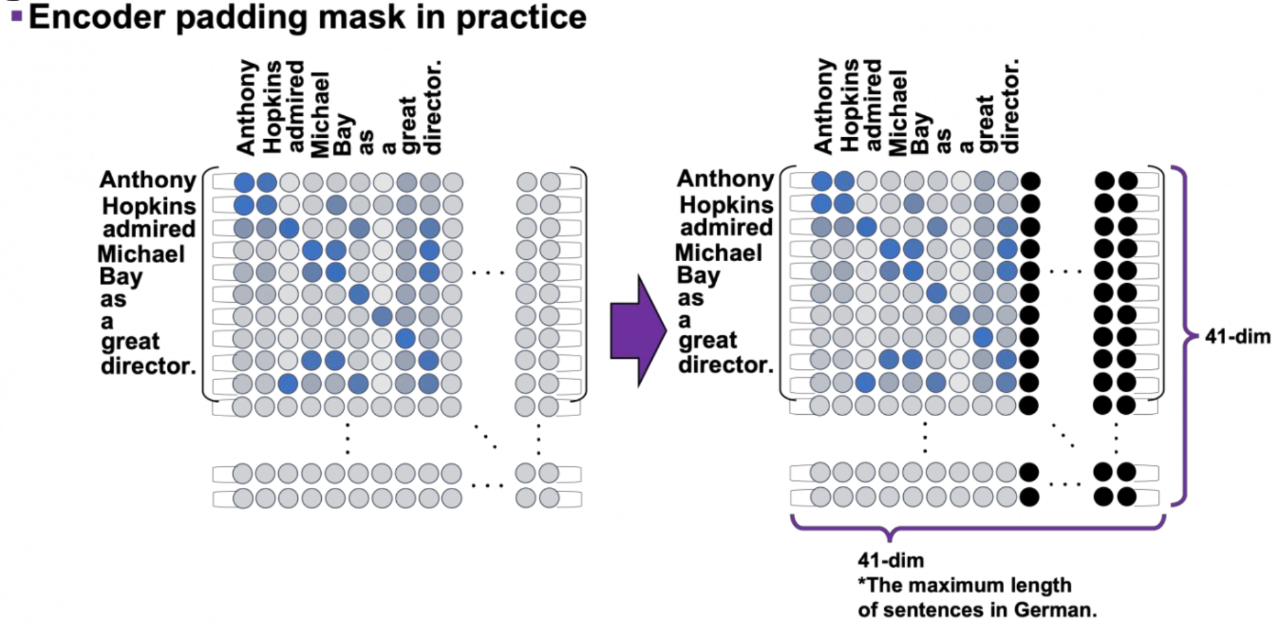
All the questions about Transformer model answered Part 5: The Padding ...
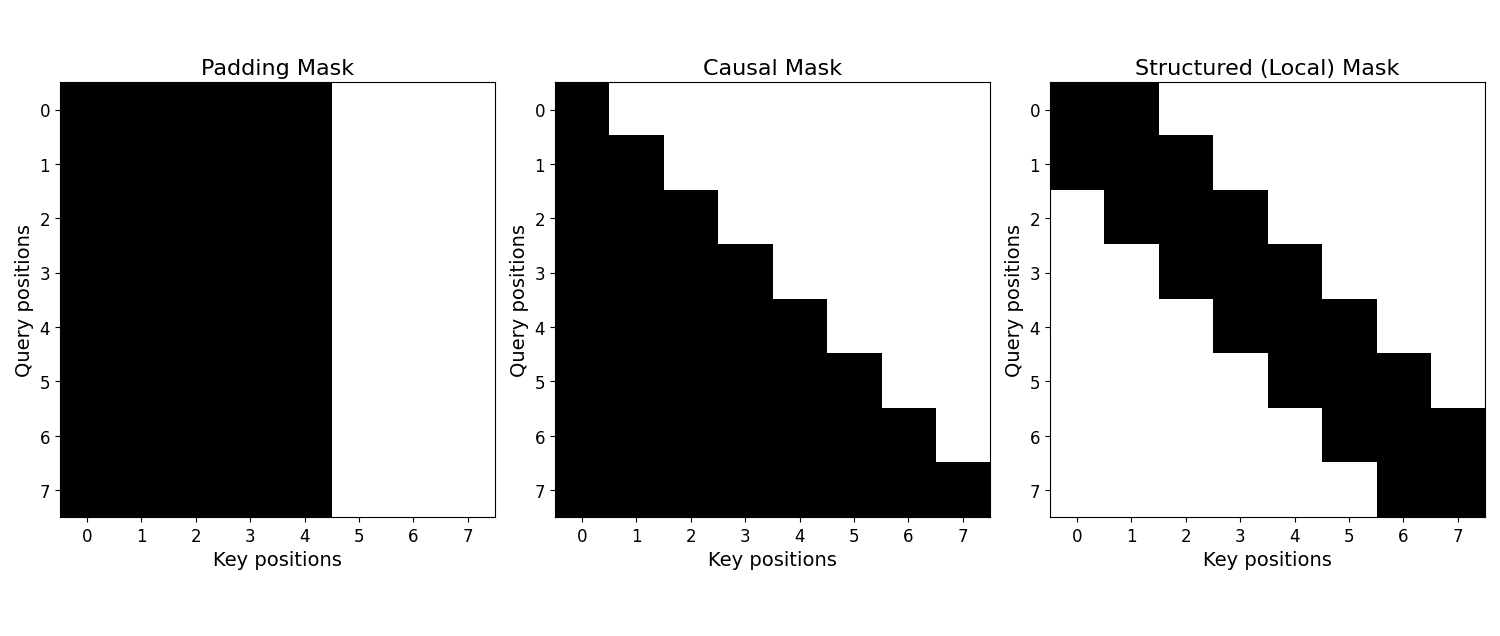
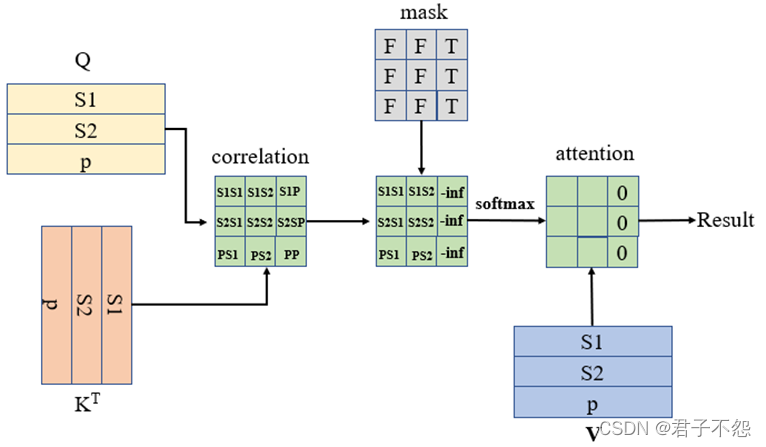
Self-attention mask schemes. Four types of self-attention masks and the ...
attention mask during training · Issue #47 · bowang-lab/scGPT · GitHub
【论文笔记】Mask2Former: Masked-attention Mask Transformer for Universal ...
【Mask Attention】Masked-attention Mask Transformer for Universal Image ...
【Transformers】警告The attention mask and the pad token id were not set ...
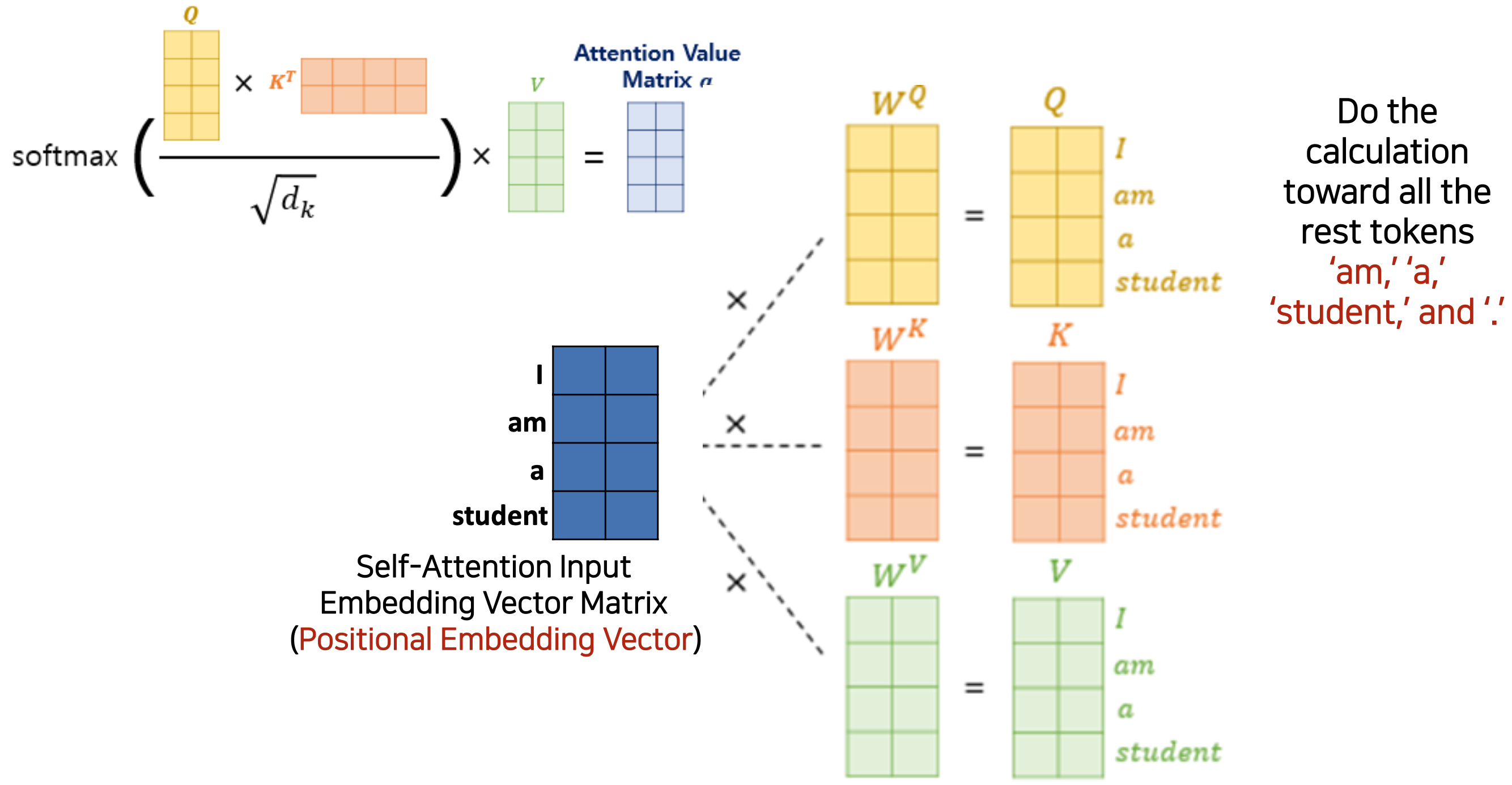
Chapter 4. Attention Value Matrix in Transformer
What Are Attention Masks? :: Luke Salamone's Blog
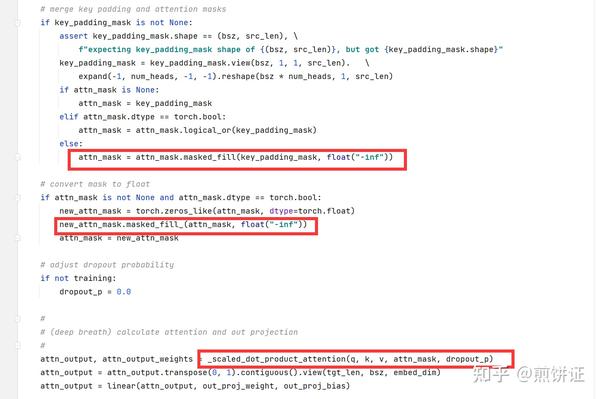
pytorch的key_padding_mask和参数attn_mask有什么区别? - 知乎
Python----循环神经网络(Transformer ----Attention中的mask)-CSDN博客
模型结构|解读transformer模型中三种attention和mask(一)_casual mask-CSDN博客
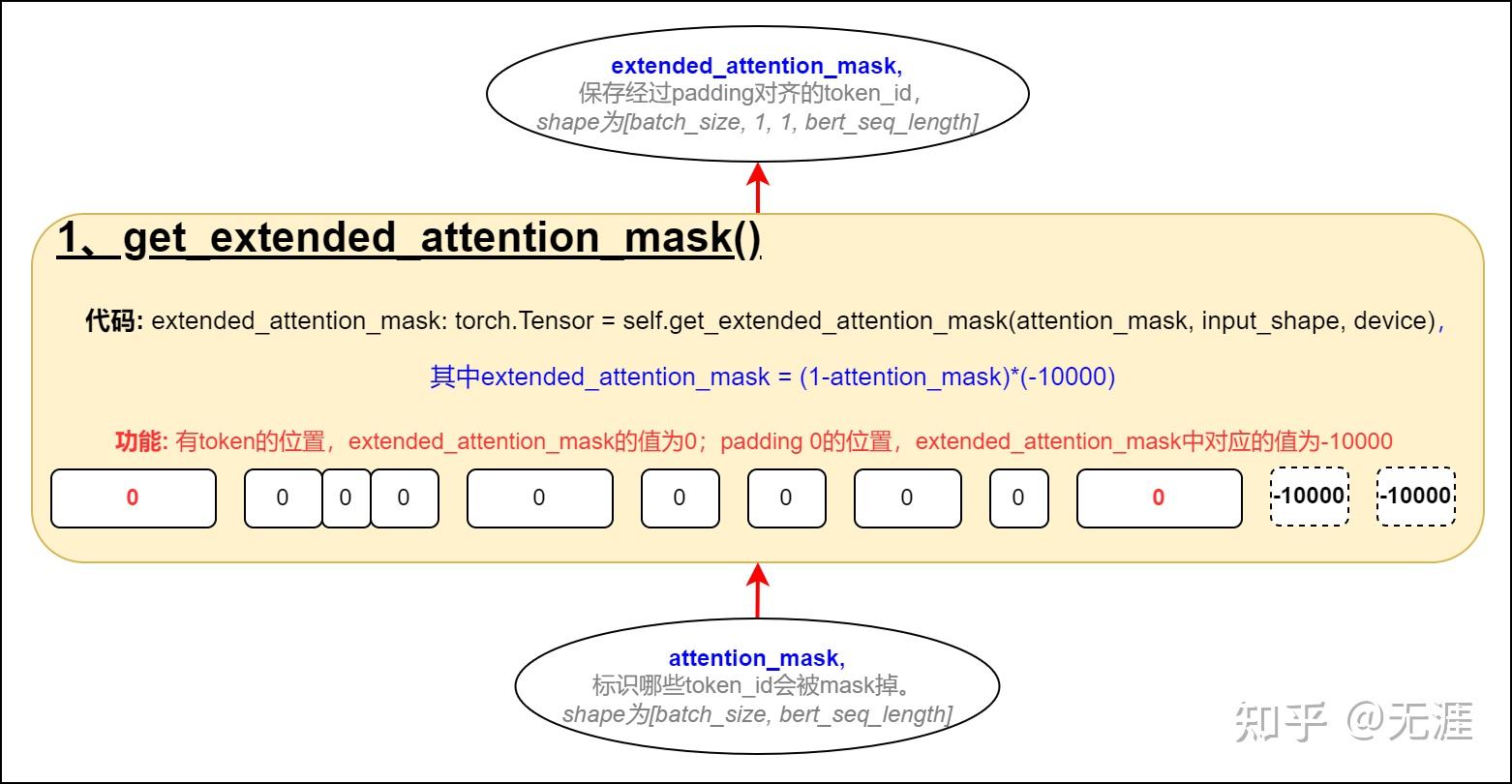
Generation of the Extended Attention Mask, by multiplying a classic ...
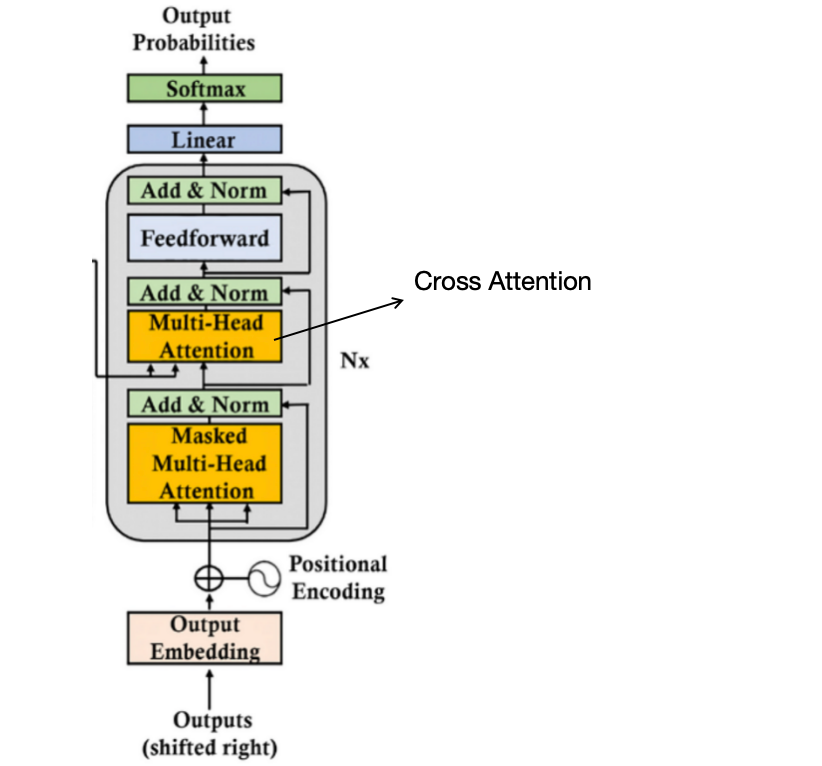
Cross-Attention: Connecting Encoder and Decoder in Transformers ...
Transformer详细解读和代码实现 - DataSense
How Do Self-attention Masks Work? - GeeksforGeeks
Example of using key_padding_mask for flash attention v2 · Issue #530 ...
Data Science Practice | Raphael Cousin Teaching
什么是Attention Mask? - 知乎
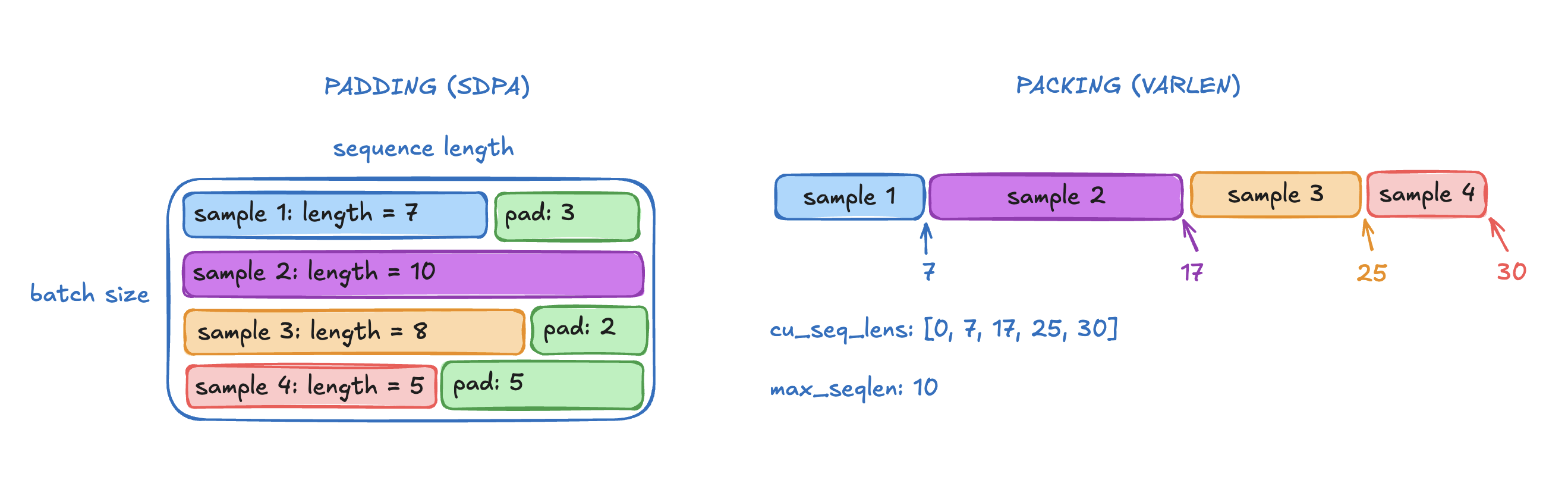
Efficient LLM Pretraining: Packed Sequences and Masked Attention
Discrepancy Between key_padding_mask and attn_mask in ...
flash attention中,softmax对padding部分的mask如何处理? - 知乎
attention_mask和padding_mask的问题 · Issue #3 · wakafengfan/unilm-pytorch ...
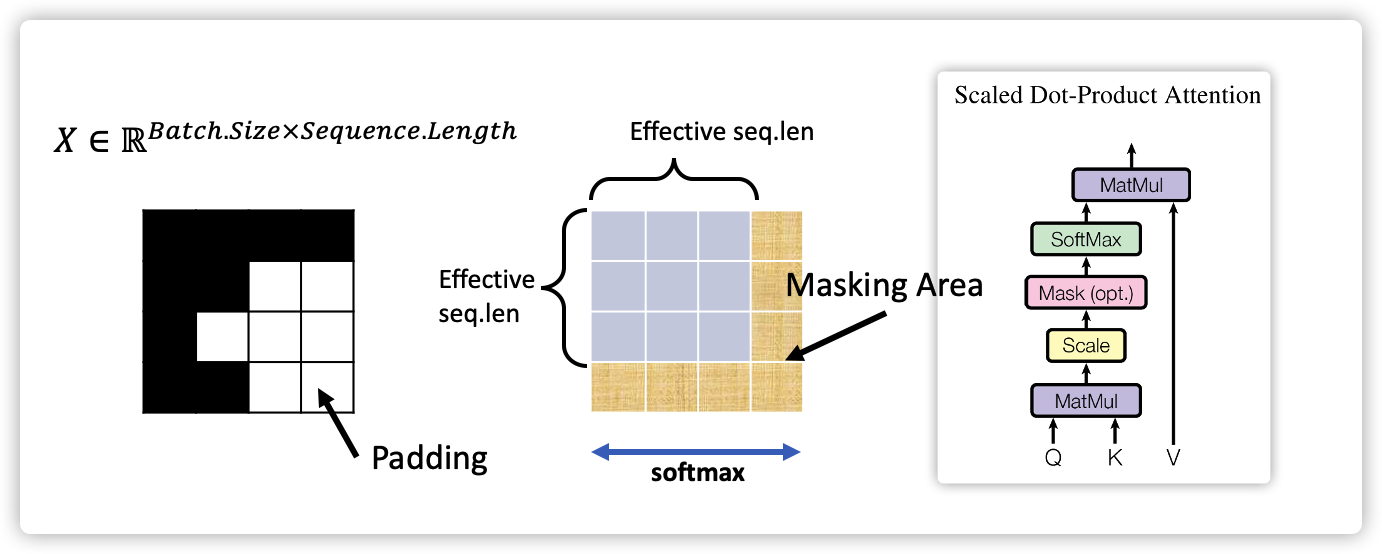
Learning JAX by Building Flexible Transformer Attention Masks: From ...
transformer中: self-attention部分是否需要进行mask? - 知乎
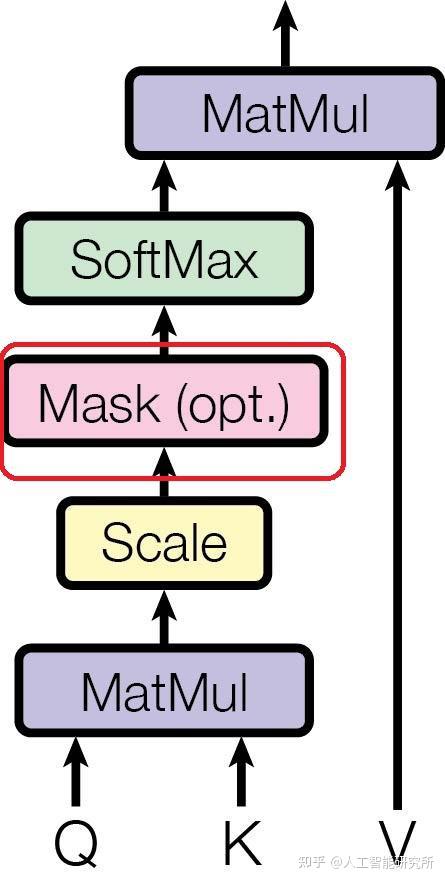
scaled_dot_product_attention实现 - 技术栈
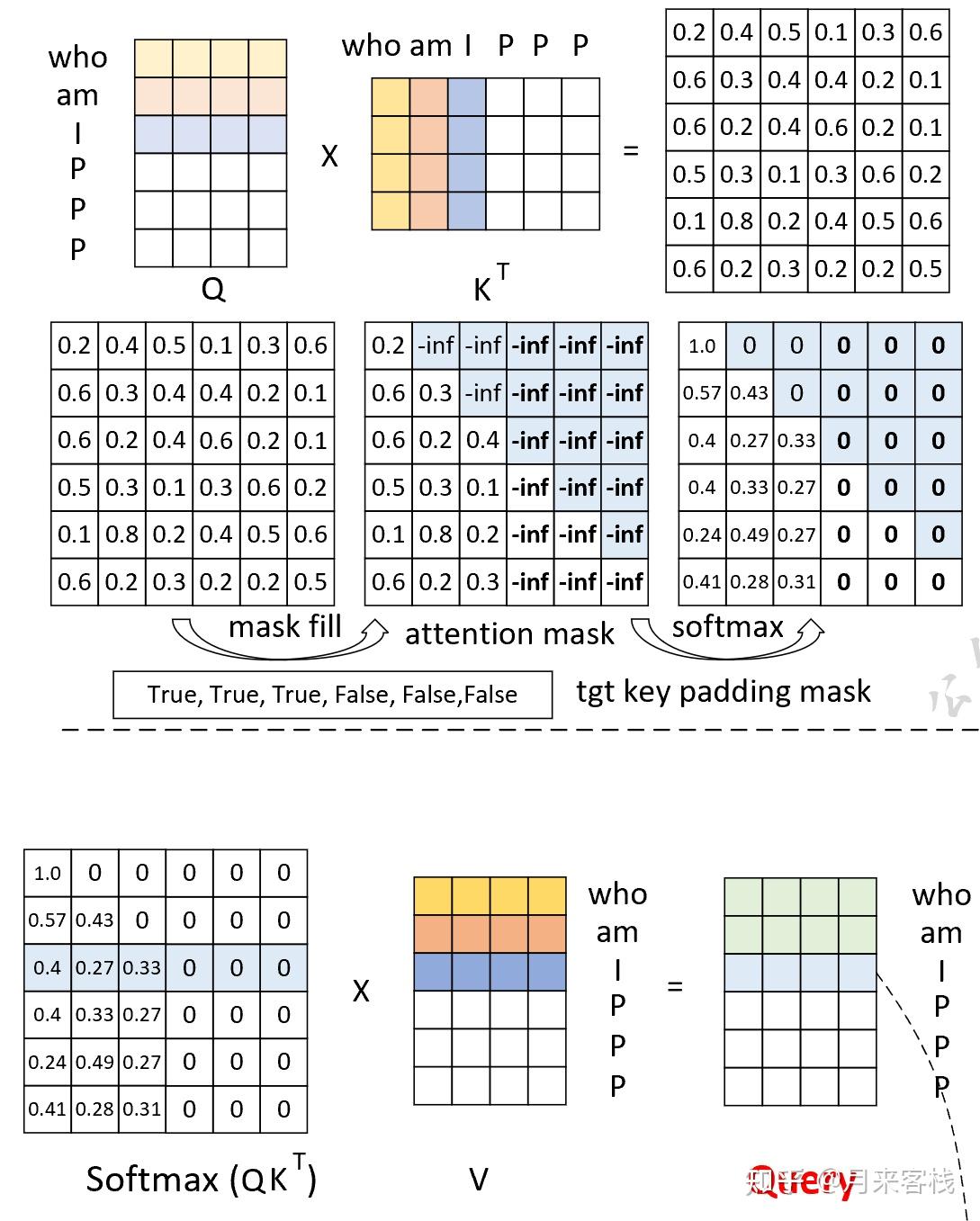
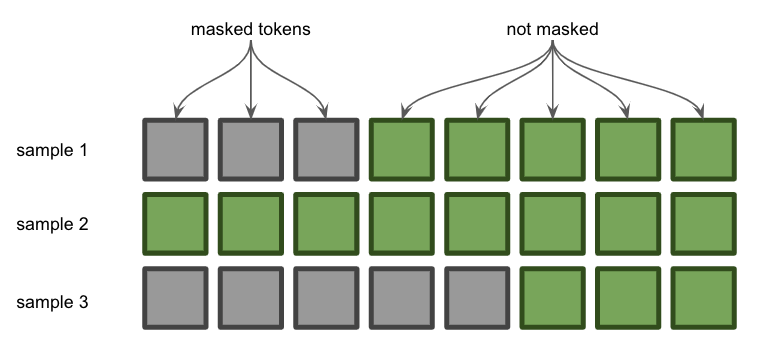
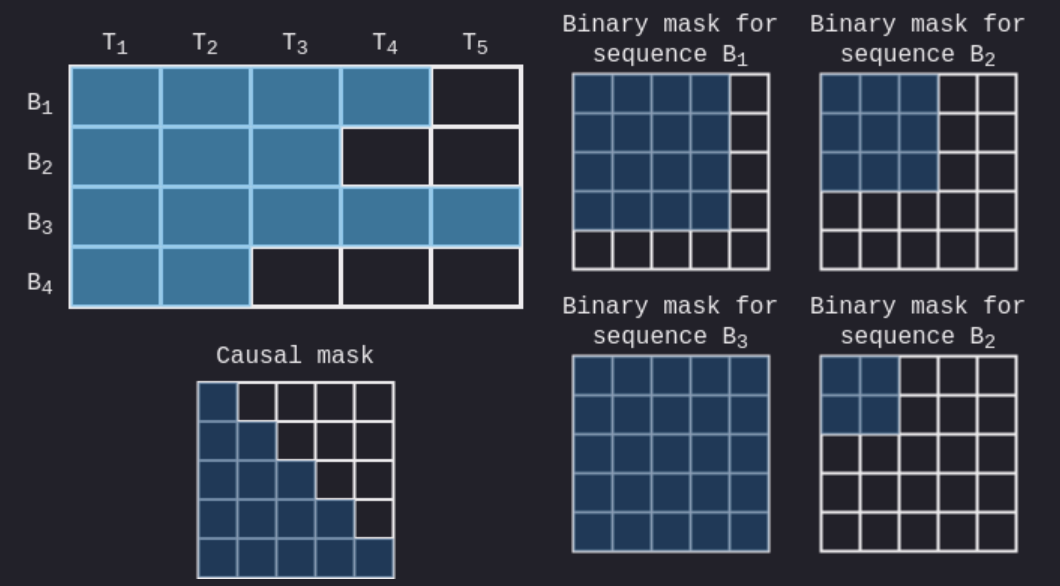
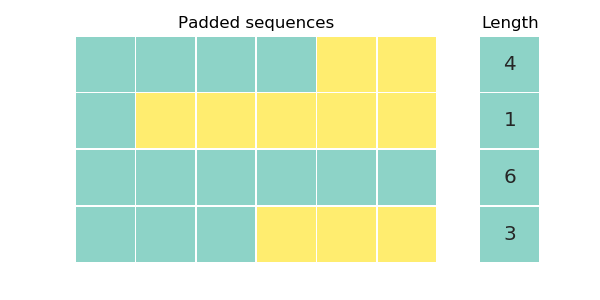
Our working example is going to be a toy dataset of 4 sequences and a ...
About key_padding_mask in multihead self attention · Issue #36 · pmixer ...
The Annotated Transformer: English-to-Chinese Translator – C. Cui's Blog
Attention-mask 在transformer模型框架中的作用_attention mask-CSDN博客
nn.TransformerEncoderLayer中的src_mask,src_key_padding_mask解析_nn ...
Transformer相关——(7)Mask机制 | 冬于的博客
4D masks support in Transformers
Function merge_padding_and_attention_mask does not return an output ...
Transformer (Attention Is All You Need) 구현하기 (2/3) | Reinforce NLP
transformer 中: self-attention 部分是否需要进行 mask?-极市开发者社区
Using Variable Length Attention in PyTorch — PyTorch Tutorials 2.11.0 ...
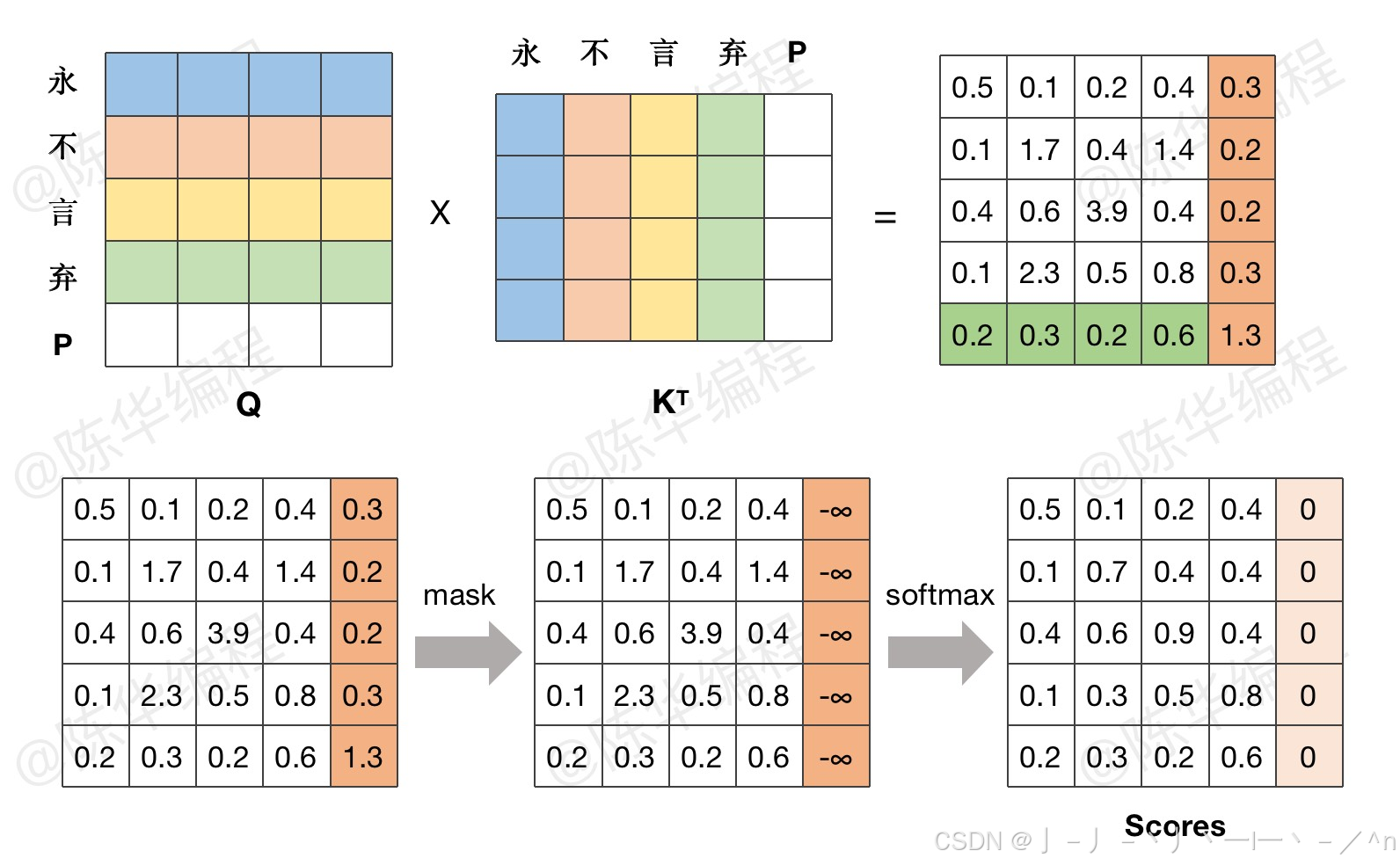
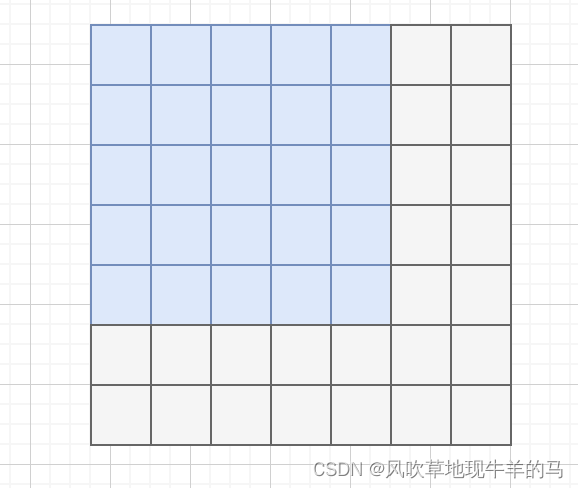
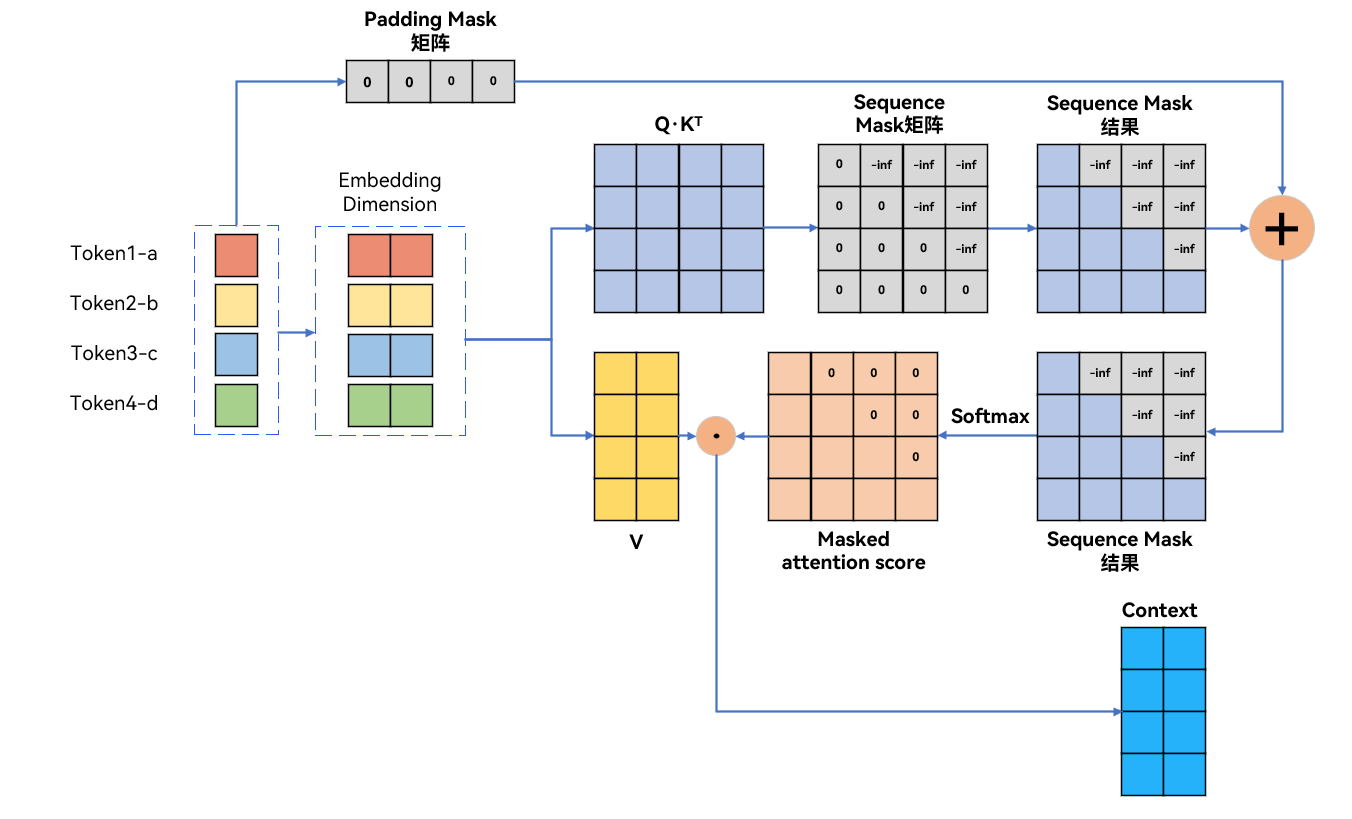
图文详解transformer模型—pad mask与sequence mask掩码张量详解 - 知乎
【通俗易懂】大白话讲解 Transformer - 知乎
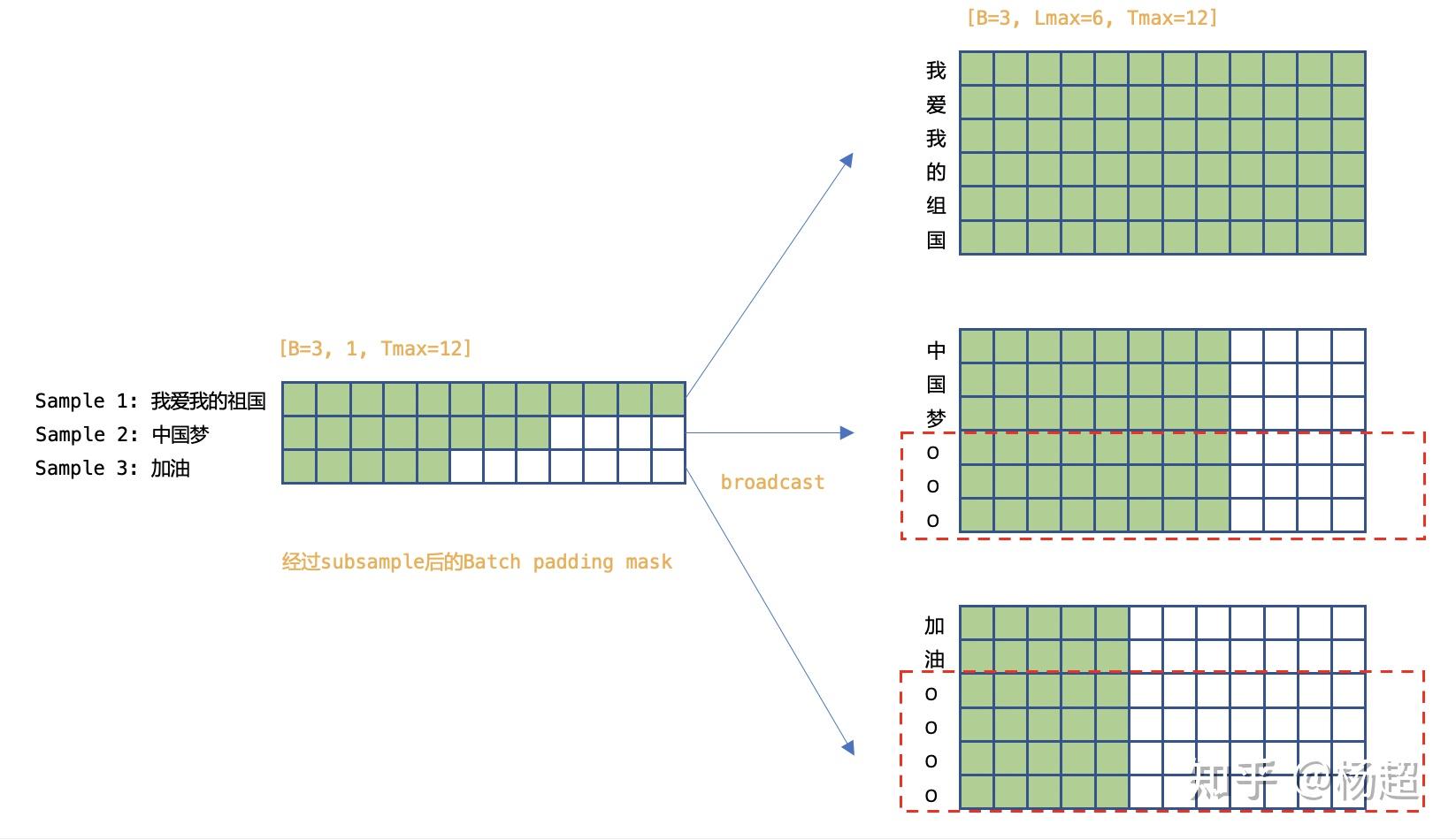
Wenet网络设计与实现3-Mask - 知乎
算法学习笔记(三)torch和HuggingFace的padding mask及attention mask的易混淆点 - 知乎
机器翻译模型四attention+pack pad sequence+mask+bleu__Pytorch实现_padding ...
Question about (padding) masking in cross-attention with transformers ...
小杰-自然语言处理(eleven)——transformer系列——Attention中的mask_attention mask-CSDN博客
[D] Causal attention masking in GPT-like models : r/MachineLearning
【Pytorch】Transformer中的mask - 知乎
极简翻译模型Demo,彻底理解Transformer - 知乎
3D Printed Masks for Special Needs – Sand Dollar Innovation
key_padding_mask is not used in the attention in fconv_self_att.py ...
How Do Self-Attention Masks Work? | by Gabriel Mongaras | Medium
Transformer 之逐层介绍 - 知乎
Huggingface Transformers学习(二)——文本分类 - 李理的博客
Improving Streaming End-to-End ASR on Transformer-based Causal Models ...
Bert是如何得到句向量和词向量的 - 知乎
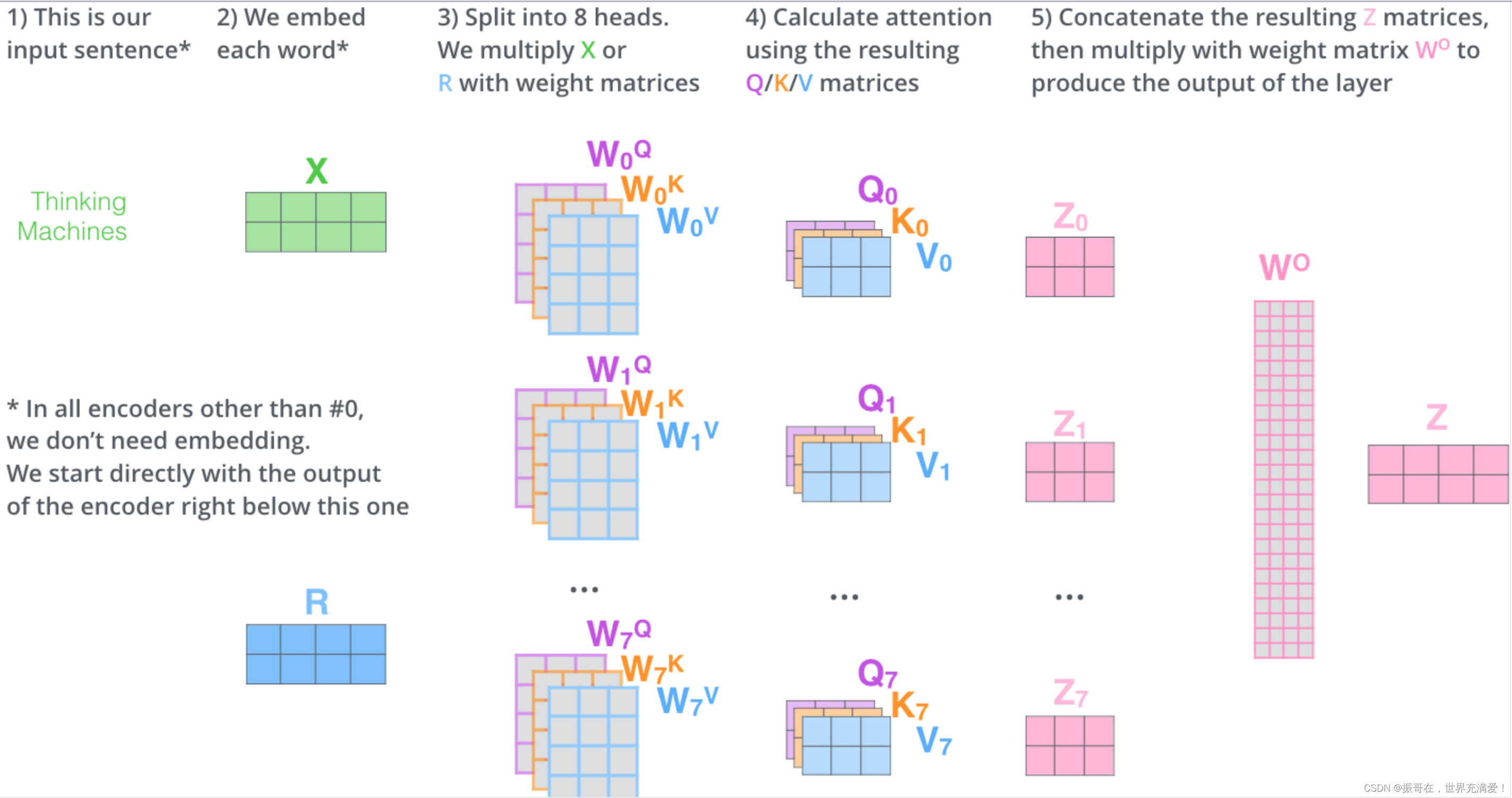
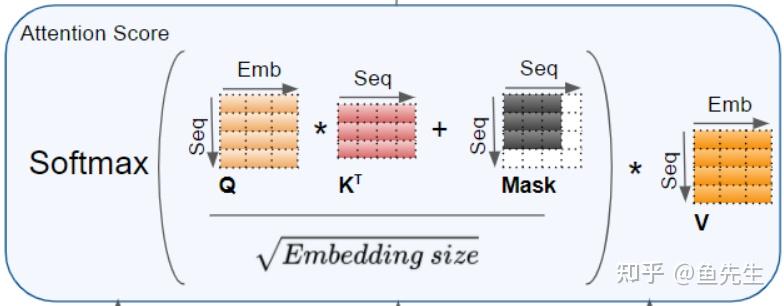
Transformers — Visual Guide
自然语言处理(NLP)-模型常用技巧:Mask【Padding Mask、Subsequent Mask】-CSDN博客
[2206.11057] Transformer Neural Networks Attending to Both Sequence and ...
Question regarding the behaviour of key_padding_mask in nn ...
Masking in Transformer Encoder/Decoder Models - Sanjaya’s Blog
Sheet 3.1: Tokenization & Transformers — Understanding LMs
Transform详解(超详细) Attention is all you need论文 - Vict0ry - 博客园
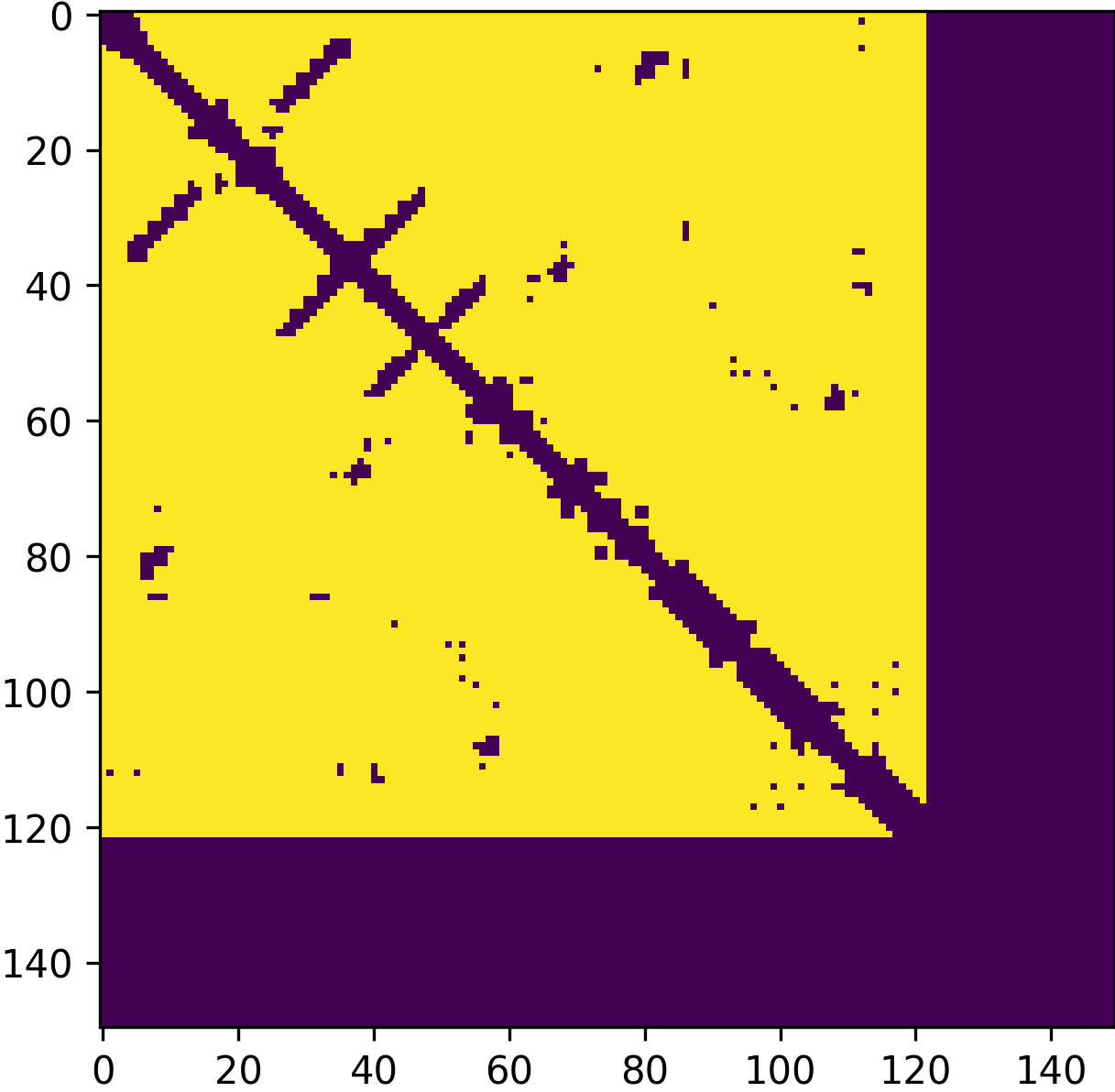
Visualization of rotated structures and attention masks. The first row ...
Transformers from scratch | peterbloem.nl
添加了Packed padded sequence和mask机制的Seq2Seq(Attention)模型_padding+sequence ...
Self-attention masks for different fine-tuning methods. Tokens in the ...
About the attn_mask · Issue #19 · facebookresearch/SymbolicMathematics ...
闻仲模型提示attention mask和pad token id问题,输出出现乱码 · Issue #319 · IDEA-CCNL ...
Bridging Autoregressive and Diffusion Models for Robust Sequence ...
Attention Is All You Need: The Original Transformer Architecture
Attention Masks — Explanation. Attention masks allow us to send a… | by ...
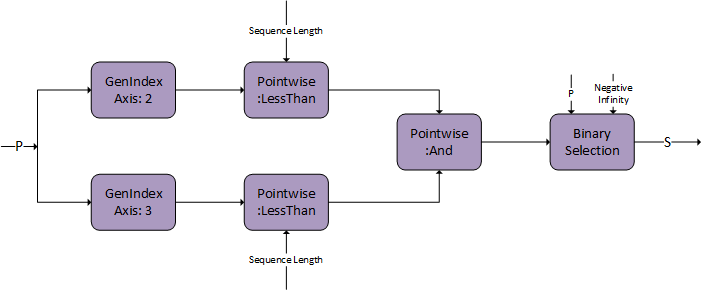
Developer Guide :: NVIDIA cuDNN Documentation
自注意力机制中的掩码Mask的生成_自注意力机制 mask-CSDN博客